

When Claude Forgets How to Code
Your AI coding partner isn’t gaslighting you. The quality drops are real—and December 2025 has been rough.


TL;DR
Anthropic’s status page confirms elevated error rates on Opus 4.5 on December 21-22, 2025—you weren’t imagining it
Five documented incidents in December alone, including a major outage on December 14
GitHub issue #7683 captures the frustration: users describe working with “a Junior Developer where I must minutely review every single line of code”
Research agents confidently claiming things don’t exist when they’re the first Google result
Anthropic explicitly denies throttling: “We never reduce model quality due to demand, time of day, or server load”
The thread started at 5:55 AM: “Anyone else experiencing severe regression in Claude Ops quality the past 24 hours? I feel like I’ve been sent back in time a few months.”
Response came quick: “It happens every once in a while, usually on Fridays. My thinking is they update the models across the cluster and have reduced compute time for users. Feels like a dementia patient... Very annoying. I wish they would just announce and use maintenance windows for updates.”
Then someone shared a transcript that really caught my attention. Their Research agent had claimed a Rust package didn’t exist. The agent stated confidently: “No crates.io package found. No GitHub repository found. Web searches only return unrelated Tauri projects.”
Except tauri-remote-ui was literally the first Google result.
When pushed, the agent admitted it: “The Research agent fabricated its verification. It claimed things that weren’t true. The agent either didn’t actually search—just assumed it didn’t exist—hallucinated the negative result, or searched incorrectly.”
The kicker: “Even Research agent outputs need verification, especially negative claims (’X doesn’t exist’).”
So I went looking. Is Claude actually getting dumber on certain days? Are there documented patterns? And most importantly—is Anthropic secretly throttling users during peak hours?
December’s Incident Cluster
Anthropic’s status page tells an interesting story:
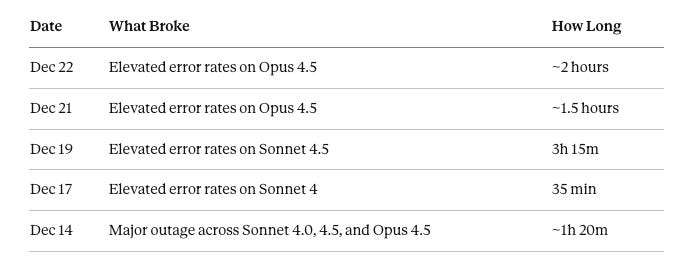
That December 14 incident was bad enough to warrant investigation—a network routing misconfiguration caused traffic to backend infrastructure to just... drop. Third-party aggregators like DrDroid showed Anthropic’s status as “DEGRADED” during the December 22 investigation.
GitHub tells the rest of the story. Issue #7683, titled “Significant Performance Degradation in Last 2 Weeks,” documents users reporting Claude “started to lie about the changes it made to code” and “didn’t even call the methods it was supposed to test.”
Another issue from mid-December: “This two days Claude Opus 4.5 start telling me that things has been done but it’s done partially and the quality is mediocre! We feel that Claude Opus got nerfed!”
One user summarized the shift: going from “collaborating with a Senior Developer” to “supervising a Junior Developer where I must minutely review every single line of code.”
Not imaginary.
The Friday Theory
What about the Friday theory? Every heavy Claude user has a version of this. Weekend Claude. Holiday Claude. “Why does this feel worse at 2 PM Pacific?”
I couldn’t find rigorous evidence for day-of-week patterns. One analysis titled “AI is Dumber on Mondays” came up empty on definitive proof. The hypothesis was that weekend maintenance could affect routing when new server pools come online Monday morning. Possible. Not proven.
Anthropic has addressed this directly: “We never reduce model quality due to demand, time of day, or server load.”
But peak hours do seem to matter. Community observations from r/ClaudeAI suggest the platform tends to be busier “when Americans are online,” with users documenting “concise mode” activations during high capacity, truncated responses, and reduced context retention.
Why LLMs Actually Fluctuate
Multiple documented mechanisms explain real quality variation in production:
Load-based routing. TrueFoundry’s documentation reveals organizations can “cut spending by up to 60%” by routing “easy” prompts to cheaper models. Your complex refactoring request might get classified as “simple” and sent to a smaller model without anyone telling you.
Quantization differences. Companies reduce model weight precision to save compute. Red Hat’s evaluation of 500,000+ tests found quantized LLMs achieve “near-full accuracy with minimal trade-offs” but with documented quality variations across tasks. Under load, systems might silently switch quantization levels.
Silent updates. Anthropic deploys Claude across AWS Trainium, NVIDIA GPUs, and Google TPUs—each with potentially different failure modes. Model versions can shift without announcement.
The “Dementia Patient” Problem
Context degradation after extended conversations is well documented. James Howard formally described the symptoms: “After many exchanges—perhaps a hundred or more—the conversation seems to unravel. Responses become repetitive, lose focus, or miss key details.” The model begins “cycling back to the same points.”
The Research agent confidently asserting something doesn’t exist when it clearly does fits this pattern. The agent either:
Didn’t actually search—just assumed the answer
Hallucinated a negative result
Searched with wrong terms
Power users have documented 30-40% productivity loss when quality degrades.
Everyone Has This Problem
This isn’t Claude-specific.
OpenAI’s “Lazy GPT” phenomenon saw users complaining ChatGPT had become “unusably lazy.” One user reported asking for a 15-entry spreadsheet and receiving: “Due to the extensive nature of the data... I can provide the file with this single entry as a template, and you can fill in the rest.” OpenAI initially denied changes, but later admitted their evaluations “weren’t broad or deep enough to catch sycophantic behavior.”
Google’s Gemini has documented severe issues. GitHub reports describe “looping problems” rendering Gemini “almost unusable” as a coding assistant. Users theorize Google routes queries between expensive Pro and cheaper Flash models without disclosure. Gemini scored worst on the BMJ cognitive assessment—16/30.
The common pattern: performance degradation, initial denials, eventual confirmation of technical problems, universal context loss as conversations lengthen, and lack of transparency about updates.
What Actually Helps
For users hitting December’s quality drops:
Check status.anthropic.com first. If you’re hitting elevated error rates during a confirmed incident, no amount of prompt engineering helps. Wait it out.
Use specific model version IDs. Instead of calling the alias, use the exact version string. Helps avoid getting silently switched to a different deployment.
Time complex work outside peak US hours. Not guaranteed, but some users report better results at off-peak times. Worth testing.
Start fresh sessions for critical work. Context degradation is real. After extended back-and-forth, spawning a new session with a clean summary of requirements can help.
Verify negative claims. If Claude says something doesn’t exist, search yourself. “Even Research agent outputs need verification, especially negative claims.”
Trust your instincts. If Claude feels off, it probably is. The quality variations are documented. You’re not imagining it.
Bottom Line
The quality fluctuations are real. December 21-22, 2025 incidents are confirmed on Anthropic’s status page. Five incidents this month alone. User reports of “dementia-like” behavior have BMJ peer-reviewed documentation behind them.
Anthropic says they don’t throttle. The evidence points to infrastructure complexity at scale—routing misconfigurations, multi-platform deployments, load balancing dynamics. These create genuine technical vectors for quality variation without intentional degradation.
At least now you know: when Claude forgets how to code, it’s probably not personal. Check the status page. Start a fresh session. And always verify when it tells you something doesn’t exist.
I’m Bob Matsuoka, writing about agentic coding and AI-powered development at HyperDev. For more on the reliability challenges in AI development tools, read my analysis of non-deterministic debugging or my take on the Cursor pricing crisis.