



The METR study finding that AI coding tools slowed experienced developers by 19% has sparked plenty of debate. But when you dig into what they actually measured—and more importantly, what they didn't measure—the results start making a lot of sense.
Here's what I think happened: They asked experienced developers to pick specific tasks from their own mature codebases, then randomly assigned AI tools on or off. The 19% slowdown wasn't because AI tools don't work. It was because they tested AI in exactly the wrong context—asking experts to use AI on problems they'd already mentally solved.
The real lesson here isn't about AI tools at all. It's that success depends more on what you choose to do, who does it, and what they're trying to accomplish than on the specific AI tool.
How I went from skeptical to convinced
I first came across this study while researching my Around the Horn piece on Monday. My initial reaction? Skepticism. A 19% productivity hit for experienced developers using AI tools? That didn't align with what I'd been observing in practice.
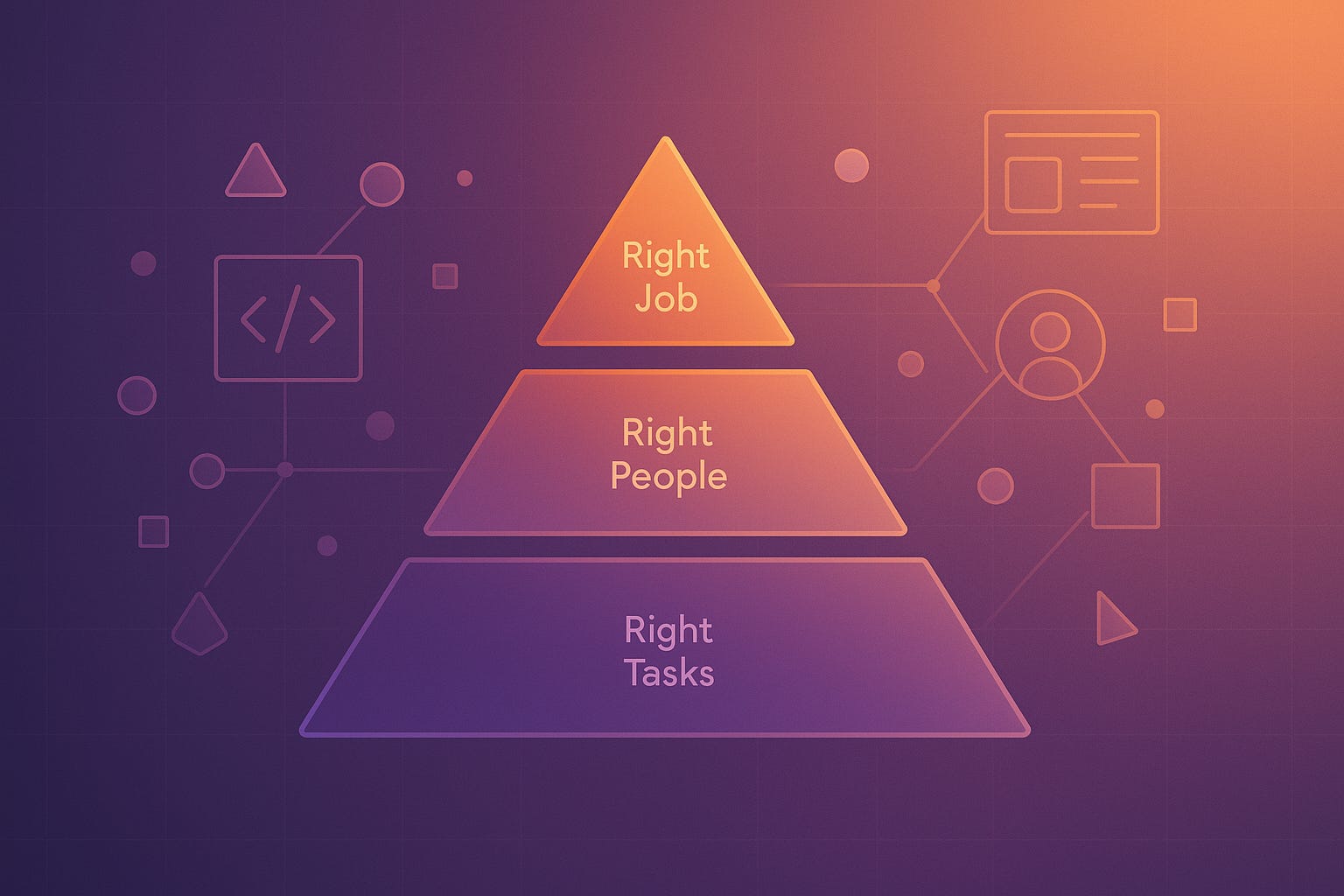
But after spending time with the methodology and validating the findings with working developers, I realized something important: this study actually validates what I've been saying for some time. The success of AI coding tools comes down to three variables—the right tasks, the right people, the right job. Let's call that the three Rs of agentic AI coding (I know they’re all “rights” but whatever - better than “TPJ”).
METR didn't measure AI tool effectiveness in general. They measured one specific scenario: experienced developers using unfamiliar AI tools on pre-selected tasks from their own mature codebases. When you frame it that way, the 19% slowdown makes perfect sense.
What the study actually tested

METR's design was solid within its constraints. Sixteen experienced open-source maintainers, working on projects averaging 22,000+ GitHub stars and over 1 million lines of code. Each developer submitted tasks from their own projects, which were then randomly assigned to allow or disallow AI tools (primarily Cursor Pro with Claude 3.5/3.7).
The within-subjects design controlled for individual skill differences effectively. Screen recording verified compliance. But here's the critical issue: developers chose their own tasks, and the evidence suggests they gamed the selection process.
Based on participant feedback and study limitations documented in the paper, developers appeared to avoid submitting anything "too important" that they couldn't risk having AI disabled. They seemed to favor "neatly packaged and well-scoped" work over the messy, open-ended challenges that represent most real development work. What they ended up testing was experienced developers being forced to use AI on tasks they'd already mentally mapped out for their specific codebase context.
This creates a fundamental mismatch. Experienced developers possess rich mental schemas of their codebases—the architectural patterns, edge cases, historical constraints, and implicit requirements that govern how code should be written. When AI suggests alternatives to their internalized approach, it becomes cognitive overhead rather than assistance.
The learning curve issue made this worse. 56% of participants had never used Cursor before the study. Adding unfamiliar tool complexity to familiar problem-solving creates a double cognitive load.
The context dependency problem
Compare METR's results with other research and a pattern emerges. Microsoft's GitHub Copilot study found 55.8% faster completion when 95 freelancers built HTTP servers from scratch—greenfield development with clear specs. Google's internal research showed 21% improvements for their engineers. Amazon's CodeWhisperer studies demonstrated 57% speedups in controlled environments.
The pattern is clear: success depends more on what you choose to do, who does it, and what they're trying to accomplish than on the specific AI tool.
Look at the variables that actually matter:
What you choose to do: Greenfield development with clear specs (Microsoft study) vs. maintenance tasks on familiar codebases (METR study)
Who does it: Freelancers of varied experience vs. experienced maintainers vs. enterprise engineers
What they're trying to accomplish: Building something new vs. improving existing systems vs. learning unfamiliar patterns
Research consistently shows different outcomes by experience level. Multiple studies document that students and junior developers achieve 40-60% productivity improvements with AI tools. Professional developers with 2-5 years experience see mixed results ranging from neutral to 30% improvements. Experienced experts working on familiar systems often see null or negative effects.
This aligns with expertise reversal theory—instructional guidance that helps novices can impair expert performance by creating unnecessary cognitive load. When you're already operating efficiently within your mental schemas, external suggestions become overhead.
But here's what the controlled studies miss entirely: many developers report scenarios where AI enables work they'd never attempt otherwise. Exploring unfamiliar frameworks, generating comprehensive test suites, diving into languages outside their comfort zone. The value often comes from expanded capability to tackle work that wouldn't happen otherwise rather than faster completion of planned tasks. This is the "what you choose to do" variable in action.
Who actually succeeds with AI tools (the "who does it" variable)
From validating these findings with working developers, I've noticed something interesting: senior leaders who understand architecture but haven't been coding regularly often have better success with AI-first approaches than working engineers. This perfectly illustrates how the "who does it" variable drives outcomes more than tool selection.
The mental schema difference explains everything. Senior architects operate at higher abstraction levels—system design, data flow, integration patterns—exactly where current AI tools excel. Working engineers have deeply internalized the specific patterns, edge cases, and constraints of their current codebase. They know which shortcuts work, which patterns to avoid, and how seemingly simple changes ripple through the system.
It's not that one group is better than the other—it's that they're trying to accomplish fundamentally different things with different existing knowledge bases.
Study participant Domenic Denicola, a Google Chrome developer, provided crucial insight. He attributed the slowdown more to "large existing codebases vs. small new codebases" and "low AI reliability" than unfamiliarity with tools. His observation that AI models are "surprisingly bad at implementing web specifications" highlights how the "what you're trying to accomplish" variable matters enormously.
The sole participant with 50+ hours of Cursor experience showed positive productivity gains, proving that the "who does it" variable includes not just expertise level, but also AI tool fluency. That's a substantial time investment—far beyond typical onboarding—required for reshaping mental models around AI-assisted workflows.
Industry adoption tells a different story
GitHub Copilot reaching 20+ million users while Stack Overflow's 2025 survey shows only 43% of developers trust AI tool accuracy seems contradictory. But it resolves when you look at use cases.
AI coding tools excel at specific scenarios: boilerplate generation (80-90% time savings according to vendor studies), documentation workflows (3x acceleration in controlled tests), test scaffolding. They struggle with complex architectural decisions, domain-specific logic, and large-scale refactoring—exactly the tasks experienced developers handle in mature codebases.
The technology eliminates repetitive work that experienced developers already complete quickly, while adding review overhead for complex tasks where human expertise remains essential. It's like having a very capable junior developer who's great at the obvious stuff but needs constant supervision on anything nuanced.
Benchmark performance shows dramatic improvements—90%+ pass rates on HumanEval versus 28% in 2021. But standardized coding challenges don't translate to real-world performance in large, context-heavy projects. The gap between benchmark success and production environment struggles creates what developers call the "almost right" problem.
The cognitive load explanation
Automation bias research shows that experts and novices both exhibit tendencies to over-rely on automated recommendations without adequate verification. You can't train this away—it's a fundamental cognitive bias.
In METR's context, experienced developers likely spent significant time evaluating and correcting AI suggestions that conflicted with implicit project requirements. Documentation standards, testing practices, architectural conventions that experts handle automatically but AI tools miss entirely.
Large, mature codebases with millions of lines of code, extensive cross-module dependencies, and project-specific patterns challenge AI's pattern recognition. While AI excels at recognizing common programming patterns from training data, it struggles with unique architectural decisions, historical constraints, and domain-specific requirements that characterize real enterprise software.
What this means for adoption

METR's findings don't invalidate AI coding tools—they highlight the importance of strategic deployment based on the three variables I've identified.
The key insight: the three Rs of agentic AI coding—right tasks, right people, right job—determine outcomes more than tool selection. AI tools work best when they expand capability rather than replace existing expertise.
This isn't about the tool—it's about context. Consider:
Right Tasks:
AI excels: Boilerplate generation, documentation, exploration of unfamiliar frameworks
AI struggles: Complex refactoring of familiar systems, domain-specific edge cases, architectural decisions requiring deep context
Right People:
AI works well: Novices learning patterns, architects thinking at system level, experienced developers working outside their comfort zone
AI creates overhead: Experts working within their existing mental schemas on familiar problems
Right Job:
AI enables: Work that wouldn't happen otherwise, rapid prototyping, comprehensive test coverage
AI hinders: Optimizing existing workflows, maintaining complex legacy systems, tasks requiring implicit project knowledge
For organizations, this reframes everything:
Stop asking "Should we adopt AI tools?" Start asking "For which tasks, with which people, trying to accomplish what?"
Measure actual productivity rather than perceived benefits (the perception-reality gap is consistent across studies)
Invest in substantial training—the 50+ hour threshold for tool fluency isn't trivial
Focus on expanding capability rather than accelerating existing workflows
The critical lesson from validating these findings: AI coding tools work when they enable work that wouldn't occur otherwise. They struggle when forced into expert workflows on familiar, complex systems where mental schemas already operate efficiently.
METR measured one specific scenario—experienced developers maintaining mature projects using tools they'd barely learned. Of course that created overhead rather than assistance. The study's outcome is consistent with what it actually measured: a context where the three Rs were misaligned.
Ultimately, the study validates the framework I've been developing around strategic AI tool deployment. The three Rs—right tasks, right people, right job—explain both METR's negative results and the industry's continued explosive adoption. Understanding when to apply AI assistance strategically, rather than assuming universal acceleration, determines whether these tools help or hinder productivity.
This analysis builds on ongoing research into AI coding tool effectiveness documented in my weekly Around the Horn series. For more practical insights on strategic AI tool deployment and hands-on tool evaluations, see the complete HyperDev archive.