


TL;DR
Same Opus 4.5 model: 96.2% (MPM orchestrated) vs 91.4% (vanilla Claude Code). Orchestration adds 4.8%.
Gemini 3 scores 76.2% on SWE-bench. Scored 44.3% in my testing. Critical bugs in every implementation.
Claude MPM beat its benchmark by 15 points. Gemini collapsed 32 points below.
Three competing AI systems—including Gemini—unanimously ranked Claude MPM first. Gemini rated its own code “needs work.”
MPM was the slowest system (127 seconds). Also produced the best code. Quality costs time.
The 0.9% gap between GPT-5.2 and Opus 4.5 on SWE-bench? Noise. The 52-point gap in practice? Reality.

The leaderboard says they’re equivalent
GPT-5.2 hits 80.0% on SWE-bench Verified. Claude Opus 4.5 sits at 80.9%. Gemini 3 Pro comes in at 76.2%.
Look at those numbers and you’d conclude the top models have converged. Pick based on price. Pick based on vibes. The capability gap has closed.
I ran a different test.
Three coding tasks—FizzBuzz, LRU cache, async rate limiter—across five systems. Same prompts. Independent sessions. No hand-holding. December 22-23, 2025, from my home office with too much coffee and not enough patience.
The results didn’t match the leaderboard. Not even close.
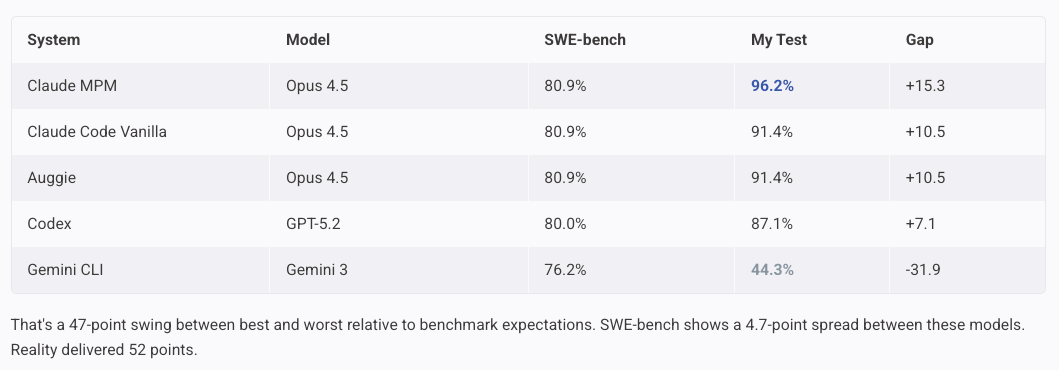
SWE-bench can’t see this. The leaderboard shows a 4.7-point spread between these models. Reality delivered 52 points.
The orchestration advantage
Three of five systems in my test run Claude Opus 4.5. Same underlying model. Same training. Same benchmark score.
Different results:

The 4.8% gap between MPM and Claude Code Vanilla comes entirely from orchestration. Research agents gathering context. Code analyzers verifying output. Structured prompts with acceptance criteria. The model doesn’t change. The infrastructure around it does.
MPM achieved two perfect 70/70 scores on the medium and hard tests. Zero bugs across all implementations. Comprehensive documentation on every file.
Here’s what that infrastructure costs: time.

MPM was the slowest system. By a lot. The rate limiter alone took 82 seconds—research, analysis, implementation, verification. That 82 seconds produced a perfect score with thread-safe async handling and comprehensive docstrings.
Gemini finished the same task in 15 seconds. And shipped a race condition.
Speed isn’t the metric.
The Gemini collapse
Gemini 3 scores 76.2% on SWE-bench Verified. Google’s marketing calls it “the best vibe coding and agentic coding model we’ve ever built.”
In my testing: 44.3%. Critical bugs in every single implementation.
FizzBuzz (the simple test): Gemini’s code prints to stdout instead of returning a list. Wrong interface entirely. Any code calling fizzbuzz(15) expecting a list gets None.
LRU Cache (medium complexity): Returns -1 for missing keys instead of None. Non-Pythonic. Breaks any code doing truthiness checks on the result.
Rate Limiter (async challenge): Missing asyncio.Lock. Under concurrent load, the token bucket corrupts. Race condition waiting to happen in production.
Three implementations. Three fundamental errors. From a model that benchmarks at 76%.
The gap between benchmark performance and practical output: 32 points. That’s not measurement noise. That’s a different capability tier.
When competitors agree, the data speaks
I had three AI systems independently review all 15 implementations. Gemini 3, Auggie (Opus 4.5 via Augment), and Codex (GPT-5.2). Each reviewed code it didn’t write.
They agreed. Unanimously.
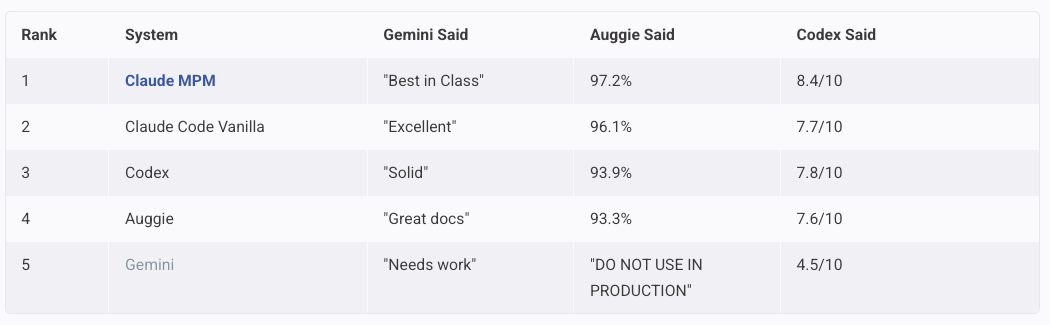
Gemini rated its own code “needs work.” Auggie flagged Gemini’s output as production-unsafe. Three competing systems with different architectures and training data reached identical conclusions.
When the worst performer admits it’s the worst performer, you’ve got objective data.

The solution leakage problem
Even SWE-bench’s narrow measurement has issues. Recent analysis found 32.67% of “successful” patches involve solution leakage—models accessing information about the fix during evaluation. Another 31.08% show suspicious patterns suggesting contamination.
That’s 64% of results potentially compromised.
Both GPT-5.2 and Opus 4.5 collapse to 15-18% accuracy on private codebases they’ve never seen. The benchmark performance doesn’t transfer. The models learned the test, not the skill.
What this means for tool selection
If you’re picking AI coding tools based on SWE-bench proximity, you’re optimizing the wrong variable.
Use Case Recommendation Why Production code Claude MPM Highest quality (96.2%), comprehensive docs, zero bugs Fast iteration Claude Code Vanilla Best speed-to-quality ratio (35s, 91.4%) Documentation-first Auggie Excellent docstrings, educational examples Type-safe prototypes Codex Strong type hints, minimal but correct Any serious work Not Gemini Critical bugs in all test implementations
The 127 seconds MPM takes isn’t wasted. It’s investment in code you won’t debug at 2 AM.
The real benchmark
Benchmarks predict neither ceiling nor floor. Good orchestration exceeds expectations. Bad implementation collapses below them. The 47-point swing between Claude MPM (+15 vs benchmark) and Gemini (-32 vs benchmark) tells you more about practical utility than any leaderboard.
The models have converged on paper. The tools haven’t converged in practice.
Orchestration beats raw power. SWE-bench can’t tell the difference.
I tested Claude MPM, Claude Code Vanilla, Augment Code, OpenAI Codex, and Gemini CLI across three Python tasks over December 22-23, 2025. Full evaluation methodology and scoring rubric available on request. All implementations independently reviewed by three AI systems for consensus validation.
I’m Bob Matsuoka, writing about agentic coding and AI-powered development at HyperDev. For more on multi-agent orchestration, read my analysis of claude-flow or my deep dive into the token economics of AI development.
Enjoyed reading through this. We need this approach when benchmarking, not the fluff! Nice work