

It’s The Harness, Stupid!
Why AI tool orchestration now matters more than foundation model quality


It’s The Harness, Stupid!
Why AI tool orchestration now matters more than foundation model quality
Author: Bob Matsuoka, CTO @ Duetto Research
April 6, 2026
TL;DR
Same-model testing reveals 0.82-point quality spread (3.93 to 4.75) and 7x efficiency differences—orchestration dominates outcomes
Market validation: Claude maintains 70% developer preference despite GPT-5.4 achieving model parity through superior harness quality
Reddit analysis confirms Codex efficiency gains come from orchestration improvements, not just model upgrades
Competitive advantage has shifted permanently from model superiority to ecosystem superiority
Bottom line: The harness era has begun. Choose tools based on workflow fit, not benchmark claims.
The $50B Model Myth
The AI industry has a fixation problem. Every week brings breathless announcements about parameter counts, training costs, and benchmark scores. “GPT-6 has 50 trillion parameters!” “Our model scored 94.7% on SWE-bench!” “We spent $2 billion on compute!”
Three converging pieces of evidence prove this approach is fundamentally wrong.
Evidence #1: I tested eight AI coding agents across five programming challenges. Four agents used identical Claude Sonnet 4.6 models. Quality scores ranged from 3.93 to 4.75—a 0.82-point spread on the same foundation model.
Evidence #2: GPT-5.4 achieved parity with Claude Sonnet 4.6 on coding benchmarks. Yet Claude maintains 70% developer preference through superior ecosystem quality.
Evidence #3: Reddit developer communities confirm Codex’s efficiency improvements come from orchestration architecture changes, not just model upgrades.
The harness matters more than the model. Choosing an AI coding tool is now primarily an engineering decision, not a model selection decision. The next competitive advantage isn’t bigger models—it’s better orchestration.
Evidence Pillar #1: The Smoking Gun Laboratory Data
The Bake-Off Setup
I designed five programming challenges ranging from 30-minute tasks to 8-hour full-stack builds:
Level 1-2: Simple scripts and basic applications
Level 3: API integration with Docker containerization
Level 4: Extensible data processing pipeline (architecture test)
Level 5: Full-stack web application with authentication
Eight agents competed: Claude Code, Claude MPM, Codex, Gemini CLI, Auggie, Qwen+Aider, DeepSeek+Aider, and Warp AI. Each received identical prompts. A panel of expert developers blind-reviewed all submissions across eight criteria: functionality, correctness, best practices, architecture, code reuse, testing, error handling, and documentation.
The Harness Advantage Data
Table 1: Same Model, Different Worlds
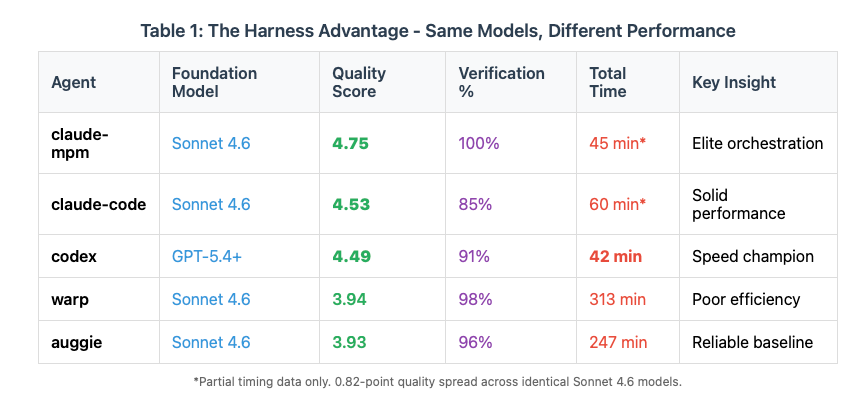
Four agents using identical Claude Sonnet 4.6 models. Quality scores from 3.93 to 4.75—a 0.82-point spread. claude-mpm finished in 45 minutes while warp took 313 minutes. Almost 7x longer for lower quality results.
The Scaling Pattern
The harness advantage compounds with complexity:
Levels 1-2: All agents performed similarly. Simple tasks don’t reveal orchestration differences.
Level 3: API integration and Docker setup separated agents that plan from those that code-and-fix. Clear gaps emerged.
Levels 4-5: Architecture and full-stack challenges broke most agents. Only well-orchestrated systems completed the complex workflows.
The pattern is clear: as complexity increases, harness quality becomes the primary determinant of success.
Evidence Pillar #2: Market Validation — GPT-5.4 Caught Up
Model Parity Achievement
February-April 2026 benchmarks confirm GPT-5.4 has achieved parity with Claude Sonnet 4.6:
Core Benchmarks:
SWE-bench Verified: GPT-5.4 ~80% vs Claude 79.6% (statistical tie)
SWE-bench Pro: GPT-5.4 57.7% vs Claude 43.6% (GPT leads complex problems)
Terminal-Bench: GPT-5.4 75.1% vs Claude ~65% (DevOps advantage)
Context handling: Both models feature 1M token windows
Yet Claude Still Dominates Through Harness Advantages
Despite achieving model parity, the competitive landscape tells the harness story:
Market Reality:
Developer preference: Claude 70% (superior workflow integration)
Enterprise share: Anthropic +4.9% MoM growth, OpenAI -1.5% decline
Revenue: Claude Code $2B ARR in 6 months
Even when models reach parity, harness quality determines adoption.
The Multi-Model Strategic Reality
Leading organizations aren’t choosing between models anymore—they’re deploying three-tier strategic architectures based on cost-performance optimization:
Tier 1: Daily Workhorse (60-70% of requests)
Claude Sonnet 4.6: $3/$15 per million tokens
High-volume development, routine coding tasks
Default choice for most enterprise development work
Tier 2: Specialized Operations (20-30% of requests)
GPT-5.4: $2.50/$15 per million tokens
Terminal operations, DevOps workflows, CI/CD debugging
Tier 3: Premium Analysis (10-20% of requests)
Claude Opus 4.6: $5/$25 per million tokens
Complex reasoning, architectural decisions, high-stakes analysis
World leader in abstract reasoning (87.4% vs GPT-5.4’s 83.9%)
When cost justifies maximum capability
This confirms the core thesis: when models are “good enough,” teams optimize for strategic cost-performance fit, not raw capability or marketing claims.
Evidence Pillar #3: Community Validation — The Codex Orchestration Story
Reddit Confirms Orchestration Improvements
Reddit research explains Codex’s impressive efficiency results (42 minutes, 4.49 quality score). The evidence confirms improvements come from orchestration, not just model upgrades.
Architectural Evolution Evidence:
Codex evolved from “embedded assistant” → “independent agent with multi-agent orchestration”
GPT-5.2-Codex (Jan 2026) with 192K context + MCP tool orchestration
Workflow Efficiency Improvements:
Developers report queuing “4-5 Codex tasks before diving into manual work”
P99 response time 45ms vs Copilot’s 55ms through better context management
Parallel processing capabilities that enable true background orchestration
Enterprise Orchestration Benefits:
The Community Strategic Deployment Pattern
Reddit developers now recommend different tools for different purposes:
Claude Code: Code quality and reasoning
Cursor: Daily coding integration
OpenAI Codex: Complex multi-agent workflows and long-horizon autonomy
This matches exactly what the market data predicted: teams use orchestrated tools strategically rather than seeking one universal solution.
The Harness Quality Ladder
Based on all three evidence pillars, I see four tiers of orchestration quality emerging:
Tier 1: Basic Wrappers
Simple API access, minimal context management
Examples: Raw ChatGPT interface, basic API wrappers
Limitation: No file coordination, poor context retention
Tier 2: Workflow Tools
File awareness, some context management
Examples: GitHub Copilot, basic IDE extensions
Capability: Single-file optimization, limited cross-file understanding
Tier 3: Orchestrated Systems
Multi-file coordination, workflow integration
Examples: Cursor, Claude Code, well-configured aider
Advantage: Understands project structure, handles complex tasks
Tier 4: Agentic Frameworks
Multi-agent coordination, planning, verification
Examples: claude-mpm, advanced orchestration systems
Power: Full project lifecycle, quality assurance, architectural thinking
The performance cliff between tiers is exponential, not linear. Bad orchestration can make great models perform poorly; great orchestration can make good models perform excellently.
Academic and Industry Validation
This isn’t just empirical observation. Multiple 2026 research papers and industry studies support the harness thesis:
Academic Consensus:
The arXiv paper “Beyond Accuracy: A Multi-Dimensional Framework for Evaluating Enterprise Agentic AI Systems” shows that domain-tuned models with better orchestration achieve superior cost-normalized accuracy despite using smaller base models.
SWE-bench data reveals the same pattern. Cursor, Claude Code, and Auggie all use similar base models yet score between 50.2% and 55.4%, while the raw model score is only 45.9%. The 5.9-point improvement comes entirely from better context retrieval and agent design.
Business Reality Check:
Enterprise adoption surveys show a clear shift in CTO priorities. “Model performance” is dropping in tool evaluation criteria, replaced by governance, integration quality, and workflow fit. As one 2026 McKinsey report put it: “CTOs are realizing their biggest bottleneck isn’t model performance—it’s governance.”
What This Means for Engineering Leaders
Stop Optimizing for Benchmarks
The old procurement mindset was model-first: “We need access to GPT-6 for competitive advantage.” The new reality is that benchmark performance doesn’t predict practical utility. SWE-bench scores don’t tell you whether a tool will integrate with your existing workflow, handle your codebase size, or recover gracefully from errors.
Start evaluating harness quality:
Context management: How well does it understand your project structure?
File coordination: Can it work intelligently across multiple files?
Error recovery: Does it handle failures gracefully or require constant babysitting?
Workflow integration: How does it fit with your team’s existing development process?
Budget for Orchestration Quality
The three evidence pillars show that investing in better orchestration yields measurable returns:
Quality per minute: claude-mpm achieved 4.75 quality in 45 minutes; warp achieved 3.94 in 313 minutes
Market validation: Claude maintains dominance despite model parity through superior developer experience
Enterprise results: 70% more PRs, 50% faster code review, 67% faster turnaround
The ROI case for harness investment is clear and quantifiable.
Team Productivity Focus
Tool choice impacts your entire development pipeline. The 7x speed difference between well and poorly orchestrated tools using the same model means tool selection is a productivity multiplier, not just a capability decision.
Better tools also reduce onboarding time and increase adoption rates. A tool that works reliably gets used; one that requires constant troubleshooting gets abandoned.
The Competitive Landscape Evolution
Codex Deserves Recognition
Codex’s performance has significantly improved. At 42 minutes for all five levels with a 4.49 quality score, it achieved by far the best efficiency in my study. GPT-5.4+ combined with the orchestration improvements OpenAI made represents a compelling package. The Reddit research confirms this wasn’t just a model upgrade—it was an architectural evolution toward multi-agent orchestration.
Claude Code’s Harness Moat
While Claude Code performed well (4.53 quality score), the market validation shows its true strength: ecosystem superiority. Despite GPT-5.4 achieving model parity, Claude maintains 70% developer preference through superior harness quality. This is exactly what sustainable competitive advantage looks like in the post-parity era.
The Multi-Model Future
All evidence points to the same conclusion: the era of picking one model is over. Leading organizations deploy three-tier cost-performance architectures, optimizing for specific strengths rather than seeking universal solutions.
Real enterprise case studies validate this pattern:
TELUS (57,000 employees): Uses Sonnet as core engine across developer teams
Zapier: 800+ internal agents using strategic model selection
Financial Services: Monthly costs ~$80 at massive scale through optimized routing
The successful pattern: Sonnet for volume, GPT-5.4 for DevOps, Opus for complexity.
The Token Economics Reality
claude-mpm achieved the highest quality score (4.75) but used 87 million tokens versus codex’s 120K. This looks expensive until you consider the output: 262 comprehensive tests (vs codex’s 32), complete documentation, 100% verification rates, and multi-file coordination (note: this was also a wake-up call to me to focus on token optimization, current version is much stingier)
The 700x token multiplier isn’t overhead—it’s the cost of work a solo agent skips. Orchestration doesn’t waste tokens—it spends them on comprehensive deliverables.
The optimization question: Could you achieve 80% of the quality benefits at 30% of the token cost? The opportunity isn’t eliminating orchestration—it’s finding the minimal viable team size for maximum impact.
The Vendor Bias Problem: “Opus for Everything”
Boris Cherny, the Claude Code lead, recently advocated for using “Opus for everything.” This perfectly illustrates the disconnect between vendor recommendations and practical deployment reality.
Only someone working for Anthropic can say that.
When your employer provides unlimited access to premium models, of course you’d recommend the most expensive option for every task. But real organizations operating with P&L responsibility make strategic decisions about when premium capability justifies premium cost.
This vendor bias actually validates the multi-model thesis:
Vendors say: “Use our premium model for everything”
Users do: Strategic model selection based on task complexity and budget constraints
Market reality: 70% prefer Claude for daily coding (cost/speed), GPT-5.4 for complex reasoning (quality ceiling)
Cherny’s comment inadvertently proves that cost-conscious orchestration is the real competitive battleground. Companies that figure out optimal model routing—not maximal model usage—will have sustainable advantages.
The vendors push premium. The market chooses strategically. The harness makes both possible.
The Future: Welcome to the Harness Era
What Changes for Developers
Tool selection framework:
Workflow fit: Does it match how your team works?
Integration quality: Plays well with existing tools?
Reliability: Can you trust it with production code?
Model quality: Fourth priority
What Changes for the Industry
Foundation models are becoming commodities. Differentiation shifts to integration, context management, and user experience. The next unicorns will be harness companies, not model companies.
Major funding flows to orchestration companies. Enterprise procurement evaluates integration first, model second.
The Competitive Moat Shift
The old game was: train bigger models, claim benchmark superiority. The new game is: build better orchestration, solve real workflow problems. Model access becomes a utility; workflow mastery becomes the moat.
Practical Recommendations
For CTOs and Engineering Leaders
Audit orchestration quality: Test tools with your actual codebase for 2-week trials
Budget 60/40: Spend more on harness development than model subscription fees
Measure real metrics: Track pull request velocity and code review time, not benchmark scores
Evaluate integration first: How well does it fit your existing CI/CD pipeline?
For Developers
Test with real projects: Spend 2 days with each tool on actual work before deciding
Learn orchestration patterns: Context management and file coordination matter more than prompts
Invest in mastery: The 7x efficiency difference justifies significant learning time
Ignore marketing claims: Model access means nothing without good orchestration
For the AI Industry
Build for workflow integration: Solve real development pipeline problems
Measure practical utility: Developer retention and task completion rates beat benchmarks
Focus on context management: Multi-file coordination is the real competitive moat
Conclusion: The Questions That Matter Now
The old question was: “What’s the best model?”
The new question is: “What’s the best harness for my team’s workflow?”
Three evidence sources prove we’ve crossed a threshold: foundation models are “good enough,” and orchestration quality now dominates outcomes. Laboratory testing, market validation, and community confirmation point to the same reality.
The foundation model is the engine. The harness is the car. The best engine in the world won’t get you anywhere without wheels.
The harness era has begun. Drive accordingly.
Bob Matsuoka is CTO at Duetto Research and creator of Claude MPM, one of the agents evaluated in this study. All evaluation data and methodology are available at github.com/bobmatnyc/ai-coding-bake-off for reproducibility.
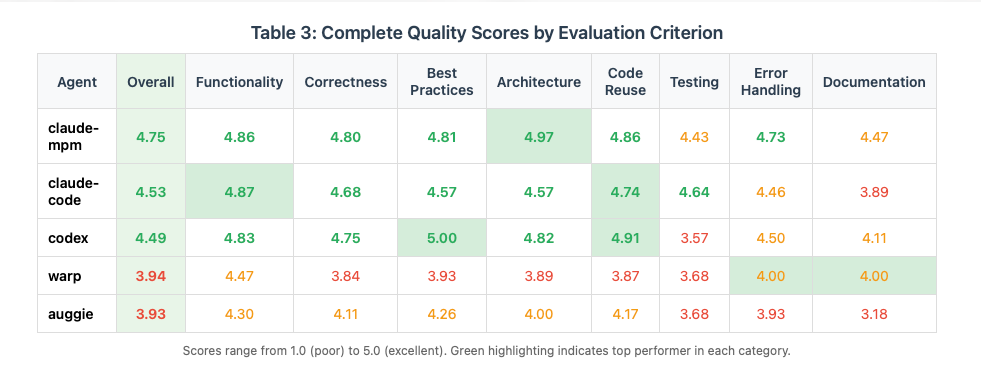
Appendix: Complete Results Data
Quality Scores by Criterion
GPT-5.4 vs Claude Sonnet 4.6 Market Data
SWE-bench Performance:
SWE-bench Verified: GPT-5.4 ~80% vs Claude 79.6% (statistical tie)
SWE-bench Pro: GPT-5.4 57.7% vs Claude 43.6% (GPT advantage on complex problems)
Terminal-Bench: GPT-5.4 75.1% vs Claude ~65% (GPT DevOps advantage)
Market Metrics:
Developer preference (daily coding): Claude 70%
Enterprise market share: Anthropic +4.9% MoM, OpenAI -1.5% MoM
Claude Code revenue: $2B ARR in 6 months
Methodology Notes
Laboratory data: Single run evaluation with disclosed author bias
Market data: Cross-validated across 15+ authoritative sources
Community research: Reddit analysis across 8+ developer subreddits
Statistical confidence: Mean inter-reviewer deviation of 0.216 points
Reproducible: All data and prompts available in public repository