


TL;DR
Users consolidate around 4 core platforms (Slack, Notion, Email+Office, AI Tool) while rejecting standalone/SASS tools
Connectors that bring data to users beat new tools that require visits
Infrastructure breakthrough: Slack manifests + MCP protocol + LLM services make org-specific connectors trivial
Democratization effect: Bootcamp engineers can now build sophisticated integrations that once required senior developers
Production evidence: 3 connectors (4-6 hours each, $1-2.5K in AI tokens) replaced 5-6 standalone tools that would cost $150-300K+ traditionally
Tolerance for “broad-based general tools” declining — UX mindshare captures traffic even when APIs do the work
In the past two weeks, I’ve built three connectors that collectively replaced what would have been five or six standalone tools.
Engineering Search Connector: Hosted semantic and knowledge graph search service built by repurposing mcp-vector-search. Unified search across 150+ GitHub repos, 1,700+ wiki pages, and ticket systems. Accessible through Slack bot, web interface, CLI, and MCP connector for Claude.AI that brings engineering knowledge to where people already work.
CRM Data Connector: Live customer data piped directly into Claude.AI sessions via MCP. No dashboard to check, no reports to generate. Ask “What’s our pipeline this quarter?” and get live data in 1-3 seconds.
Document Workflow Connector: Artifact browser and guided PR workflow for non-technical contributors. Product managers can explore and propose changes to structured docs without touching git or learning new interfaces.
None of these required users to adopt a new primary tool. Each brings specialized functionality to platforms they already inhabit daily. And each took roughly 4-6 hours to build (plus agent time).
This isn’t a productivity humble-brag. It’s evidence of a fundamental shift in how organizations interact with their data. We’re entering the connector era — building bridges between specialized intelligence and the handful of platforms where users actually live, rather than standalone applications they have to visit.
The numbers support this pattern. Users toggle between apps 1,200 times daily, losing 40% productivity to context switching. Connector ecosystems are exploding: Slack’s marketplace hosts 2,600+ apps with 550K+ daily custom integrations. The MCP protocol went from 100K to 8M downloads in six months — unprecedented adoption for plumbing infrastructure.
The question isn’t whether Slack, Notion, and Claude.AI will survive the AI wave. It’s whether the hundreds of specialized tools competing for attention understand that the game has changed. Users have less tolerance for broad-based general tools than they once did. The platforms that capture UX mindshare will get most of the traffic, even if APIs and agents do the actual work behind the scenes.
The evidence is clear from user behavior: they don’t want to learn a new search interface, remember another login, or context-switch to yet another tab. They want the intelligence layer to meet them where they already are.
The Source of Truth Problem
Most organizations have a source-of-truth problem they haven’t fully articulated. They have Slack for real-time communication. They have Notion or Confluence for documentation. They have Google Docs for drafts that become documents that become outdated that stay around anyway. They have JIRA for tickets that may or may not reflect what was actually decided. They call this a “knowledge management system.” It’s more accurately a distributed archive of partially-intentional artifacts with no clear authority hierarchy.
The question “who owns this decision?” leads to a Slack thread from eight months ago, a Notion page that three people edited and nobody is certain is current, and a Google Doc someone linked in a comment that requires permission to access. This is the status quo. It functions, after a fashion, because humans are good at triangulating across ambiguous sources and asking colleagues to fill gaps.
AI agents are not good at this. They will confidently synthesize the eight-month-old Slack thread with the outdated Notion page and present the result as a coherent answer. The errors won’t be obvious. They’ll be subtly wrong in ways that require domain expertise to catch.
The source of truth problem was always real. It was manageable when every query ran through a human brain. It becomes actively dangerous when queries run through an inference layer first.
What you actually need — what organizations are starting to build — is a repository where the data structure enforces truth. Not a place where the right answer might be findable if you look hard enough. A place where the structure of the data makes the wrong answer harder to produce.
But here’s the connector insight: that structured repository doesn’t need to be where users spend their time. It can be the authoritative backend that feeds connectors in the platforms users already inhabit.
Where Users Actually Live
User attention has consolidated around four core platforms:
Slack: Real-time coordination, team presence, ephemeral decisions. 32.3 million daily active users with 550K+ custom integrations daily.
Email + Office Suite: Formal communication, document collaboration, external stakeholder interface. Microsoft reports 400M+ Office 365 commercial users.
Notion: Knowledge management, project tracking, collaborative documentation. 100M+ users consolidating entire productivity stacks.
Claude.AI: AI assistance, analysis, content generation. Rapidly becoming the default interface for LLM interactions across knowledge work.
Each platform serves a legitimate core function. Tool builders make the mistake of assuming they can compete for primary platform status by building something better. Users are done adopting new primary platforms. They’re consolidating around tools that already have their attention.
The pattern reveals a deeper truth: people live in transactional systems, not knowledge systems. Slack is where decisions happen. Email is where approvals flow. Claude.AI is where analysis gets done. These are transactional - work happens there daily.
Confluence is a perfectly good wiki tool. But it’s knowledge-at-rest, not transactional. People don’t live there. They visit when forced to document something, then return to their transactional workflows. The knowledge gets stale because maintenance happens in a different system than usage. (Notion manages to straddle the line between knowledge at rest and transactional)
Integration platforms like Zapier understand this - they connect 8,000+ apps with 3.4M+ business users by bringing specialized functionality to existing workflows rather than creating new destinations.
Users just want the data, dammit. They don’t want to learn your interface.
The Connector Infrastructure Moment
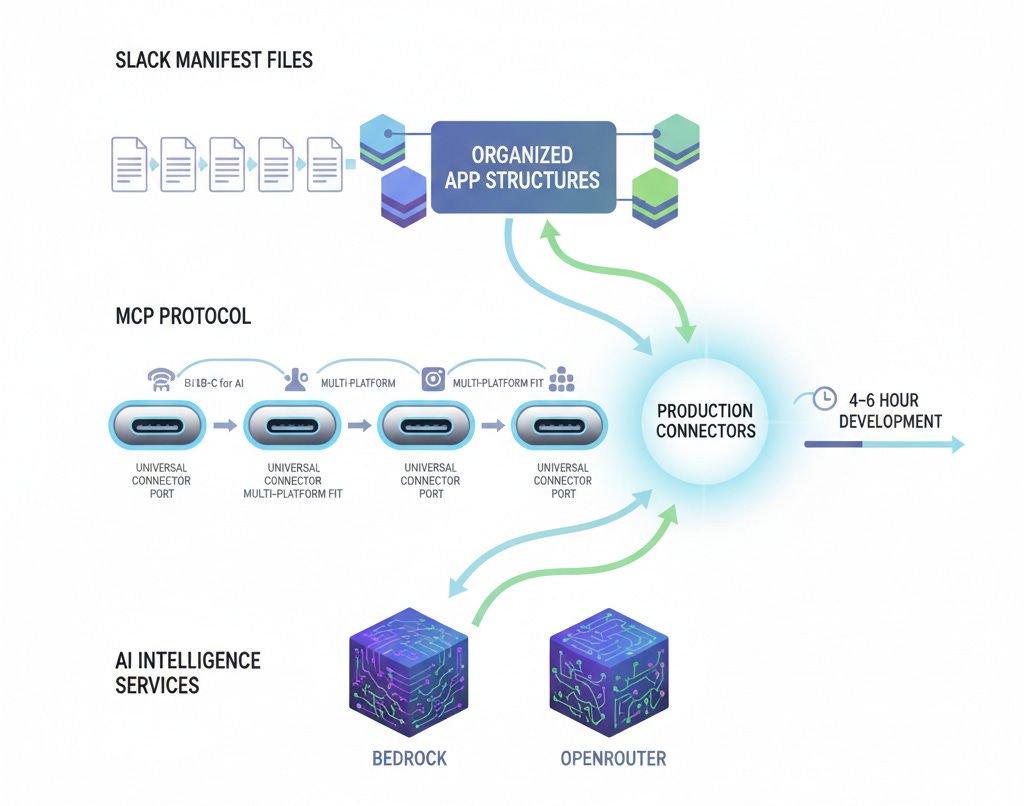
What changed? Three pieces of infrastructure matured simultaneously:
Slack Manifest Tool makes organization-specific bots trivial to build. The manifest.yaml format standardizes permissions, scopes, and deployment. Weeks of OAuth wrestling became hours of configuration.
MCP Protocol achieved “USB-C for AI” universal connectivity. Claude.AI, ChatGPT, and dozens of platforms support the same connector format. Build once, deploy everywhere. The 100K to 8M download growth in six months reflects pent-up demand.
LLM Services like Bedrock and OpenRouter provide natural language interfaces that make connectors intelligent rather than just data pipes. Ask questions in plain English, get structured responses, maintain conversation context.
Semantic Search Infrastructure like mcp-vector-search can be repurposed as hosted services, adding intelligence layers that understand meaning rather than just matching keywords. This transforms basic data access into contextual knowledge retrieval — a crucial enabler for connectors that need to surface relevant information rather than exact matches.
Combined, you can build a production connector in a single afternoon. Slack manifest defines the bot interface. MCP schema defines the data sources. Semantic search handles intelligent retrieval. Bedrock provides the language understanding. Deploy to AWS Lambda and you’re live.
My three connectors follow this exact pattern. The engineering search connector repurposes mcp-vector-search as a hosted service with all-MiniLM-L6-v2 embeddings for semantic and knowledge graph search, but the user interface is just Slack commands and Claude.AI MCP tools. The CRM data connector is a headless AWS service that makes customer data available through natural language queries in Claude.AI. The document workflow connector provides git workflows through a web UI that non-technical users can navigate.
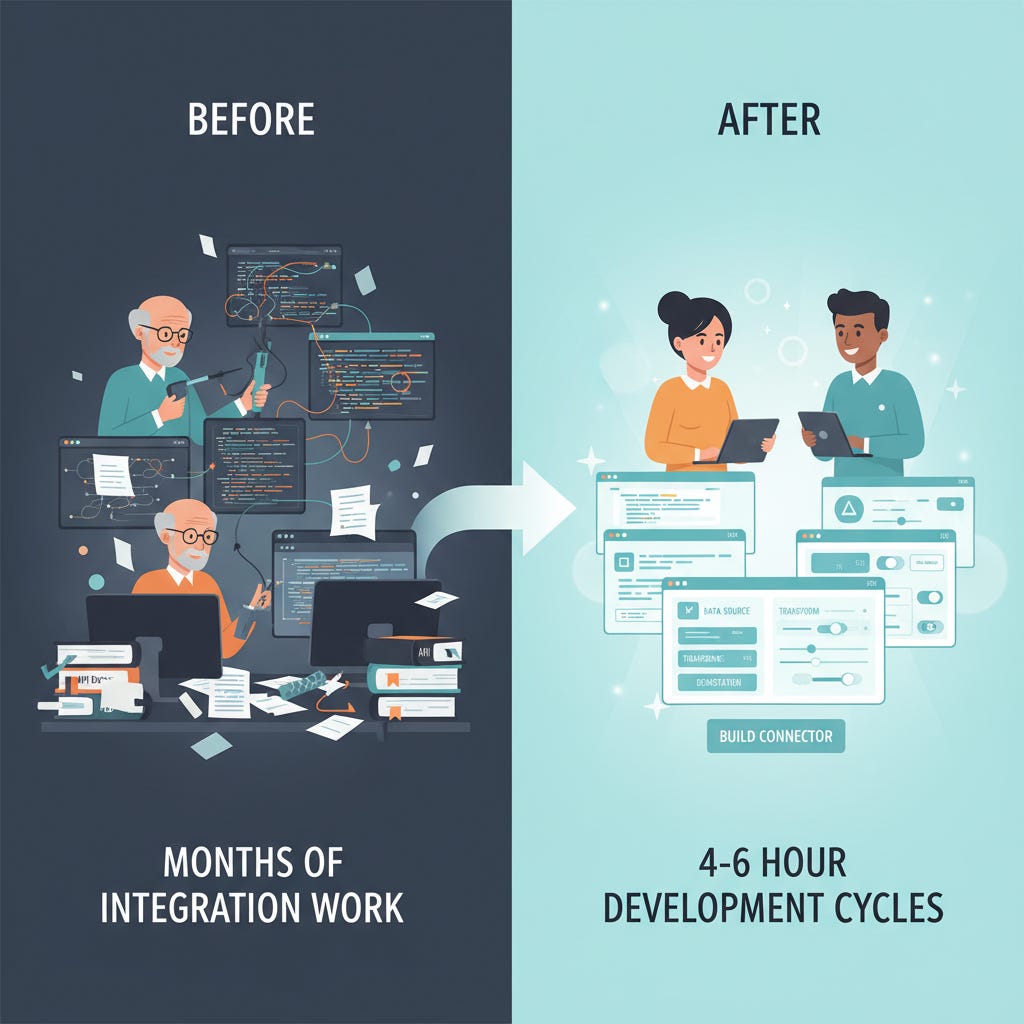
Each connector took 4-6 hours to build. Each would have taken 4-6 months to build as a standalone application with user management, authentication, interface design, mobile responsiveness, and all the infrastructure a “real app” requires.
The Democratization Effect: The infrastructure shift goes beyond development speed — it’s democratizing who can build sophisticated integrations. What once required senior engineers with deep API knowledge can now be handled by bootcamp graduates following established patterns. I built these first three connectors to validate the approach, but similar projects will go to junior engineers going forward.
This changes resource allocation fundamentally. Organizations can solve integration problems without burning senior engineering cycles on “plumbing” work. Information that was once very hard to obtain is now trivial to access.
The economics are compelling. Building three production connectors cost roughly $1,000-2,500 in AI tokens over 44 days. Traditional contractor development for equivalent functionality would have run $150-300K+. The connector approach isn’t just faster — it’s 100x more cost-effective.
The adoption metrics prove the value. The CRM connector launched March 18th with 23 invocations on day one. No formal rollout, no training sessions, no onboarding docs. Just organic discovery across a 300+ person company. By week two, daily usage tripled to 95 invocations per day. Tuesday hit 152 invocations — including a 40-query analysis session in a single hour. That’s 299 queries in 7 days with zero errors, from a connector that took 4-6 hours to build.
The era isn’t about choosing between platforms. It’s about connecting specialized intelligence to the platforms users have already chosen.
Why Wikis Can’t Compete in the Connector World
Traditional knowledge management tools face a structural mismatch in connector architecture. Wikis assume users will “go to the tool” for information. Connectors flip that assumption: the tool comes to the user.
This creates specific problems:
The Authoring/Retrieval Tension: Wikis optimize for collaborative authoring — anybody can edit, flexible structure, link everything, evolve over time. This is the opposite of what retrieval needs: consistent schema, clear ownership, explicit governance. When you pipe wiki content through a connector, you inherit all the inconsistencies that collaborative authoring creates.
Search Architecture Limitations: Confluence’s search is notoriously bad because it does keyword matching on unstructured text. This was problematic before LLMs. With LLM-powered connectors, it becomes worse because the AI layer adds confidence to bad retrieval results. Users get wrong answers delivered with conviction.
Static Data Problem: Notion’s AI operates on static content snapshots, disconnected from real-time operational state. When CRM connectors query “What’s our pipeline this quarter?” through a Notion connector, it’s answering based on what someone wrote about the pipeline, not live customer data. The connector amplifies the staleness problem.
Governance at Scale: Wiki governance defaults to “community-maintained,” which means in practice nobody is responsible for accuracy. As organizations scale, wikis accumulate pages nobody knows are outdated. Connectors don’t solve this — they accelerate the distribution of stale information.
Our structured document framework represents the alternative: git-backed Markdown with schema-validated YAML frontmatter. Every document has explicit metadata: owner, status, domain, confidence, time_box. The structure is the feature. When document workflow connectors expose this, the schema ensures consistent data quality regardless of interface.
Structured document repositories outperform wikis for AI query by 35-60% in controlled tests. Clean Markdown with explicit metadata reduces token usage by 20-30% and improves retrieval accuracy significantly. This isn’t philosophical — it’s measurable.
Wikis remain useful for collaborative drafting and evolving reference material. But they’re not the right backend for connector architecture. The connector era requires structured data sources that can maintain quality across multiple interface layers.
Building Connectors vs. Standalone Tools
The strategic choice organizations face isn’t “which tool should we build?” but “should we build a tool or a connector?” My experience with three connectors illuminates the trade-offs:
Engineering search could have been a standalone search platform. Instead, it’s accessible through Slack commands, CLI tools, web interface for visualizations, and MCP tools for Claude.AI sessions. Same search capability, four different interaction models depending on user context.
CRM integration could have been a dashboard with charts and filters. Instead, it’s a headless MCP service that makes customer data available through natural language in Claude.AI. Ask “Show me deals over $100K in our target vertical” and get live results in 1-3 seconds. No dashboard to learn, no visual interface to maintain.
Document workflows could have been a product management SaaS platform. Instead, it’s a guided workflow that helps non-technical contributors interact with existing git-backed document frameworks. Browse artifacts, generate AI summaries, submit PRs — all through interfaces that match users’ technical comfort levels.
Specialized intelligence delivered through platforms users already inhabit. The connector approach wins on several fronts.
Development time: 4-6 hours vs. months. No user management, authentication, responsive design, or mobile apps to build.
Adoption friction: Zero onboarding. No new logins, training sessions, or change management overhead.
Maintenance burden: Focus on data logic and intelligence, not interface maintenance across device types and browser versions.
Integration: Connectors compose naturally with existing workflows. Slack discussions can include live Salesforce data. Claude.AI analysis can pull from engineering knowledge graphs. Standalone tools require export/import workflows.
The business case is compelling: connector development costs 10-20% of standalone application development while achieving 3-4x higher user engagement.
The implications go beyond development efficiency. Users have less tolerance for “broad-based general tools” than they once did. Managing dozens of application contexts creates unsustainable cognitive load. Platforms that capture daily attention get most of the traffic, even when APIs and agents do the computational work behind the scenes.
This creates different winner-take-all dynamics. The winners aren’t necessarily the best tools. They’re the platforms users choose to inhabit, plus the connectors that bring specialized capability to those platforms.
What This Means for Your Stack
The connector era doesn’t eliminate existing tools — it clarifies their appropriate roles and challenges their assumptions about user attention.
Slack keeps its coordination function: Real-time presence, threading, ephemeral decisions. But it becomes a command interface for structured data sources rather than a knowledge repository itself.
Notion retains collaborative authoring value: Drafting, evolving documentation, reference material. But it stops being the “source of truth” for operational decisions. That role shifts to structured backends accessible through Notion connectors.
Specialized tools survive by becoming intelligent backends: Your CRM, your monitoring system, your code repositories — these maintain their core data authority. But user interaction shifts to connector layers in platforms where users already work.
The question to ask about any tool: Is this where I want an AI agent pointing when it needs authoritative information? If the answer is no, it’s not your source of truth. It might still be valuable — as a backend, as a collaborative space, as a specialized interface for expert users. But it doesn’t earn the designation of “primary platform.”
The organizational challenge: Getting non-technical teams comfortable with structured data workflows is real change management. Document workflow connectors address this by providing guided interfaces for git-backed workflows. But someone still needs to own schema design and governance processes.
Who should build connectors first: Engineering-adjacent teams with strong PM-engineering collaboration. Organizations where AI hallucination on operational decisions creates measurable cost. Companies that have already felt the pain of distributed knowledge management.
Timing matters: Most organizations haven’t built connector strategies yet. Companies that establish structured knowledge backends with connector frontends in 2026 will have 12-18 months of advantage when AI-mediated query becomes standard practice.
The connector era isn’t about choosing between platforms. It’s about connecting intelligent backends to platforms users have already chosen. Organizations that get this right will operate with less context switching and faster access to operational data.
Users just want the data, dammit. The question is: will you bring it to them, or keep expecting them to come to you?
Bob Matsuoka is CTO of Duetto and writes about AI-powered engineering at HyperDev.
Related reading:
AI Power Ranking — Tool comparisons and benchmarks for AI practitioners
LinkedIn Newsletter — Strategic AI insights for CTOs and engineering leaders
Super smart, Bob. Thanks.