

Every Claude.AI Tab You Open Gets Its Own "Server"
(Yes, really..I think - but I have evidence, follow along!)


I noticed that a Claude.AI webpage behaved like a (server) container. That was surprising. Tested container isolation between Claude.AI tabs. Found different containers. Did not expect that.
Then checked the hostname in a fresh tab—before creating any artifacts or running anything. gVisor was already there. Already running.
That changed what I thought I understood about the architecture. Then I realized I was misunderstanding what that architecture actually costs.
TL;DR
Every Claude.AI page load allocates a gVisor sandbox with isolated filesystem, process namespace, and up to 9GB memory limit—verified through repeated testing
gVisor sandboxes ≠ VMs: Lightweight userspace isolation running thousands per host, sharing base images, allocating memory on-demand—not dedicated 9GB per tab
My initial cost estimates were probably wrong by 10x+: Naive VM pricing (~$0.06/hour) dramatically overstates actual infrastructure costs for this architecture
The UX bet remains real: Pre-allocation means zero latency when you need containers, but actual unit economics are likely far better than my initial modeling suggested
Still explains infrastructure investment: Even with better-than-VM economics, scale drives need for owned infrastructure—just not as dramatically as first calculated
The Container Allocates on Page Load
Two tabs. Different conversations. Tested the isolation:
# Tab 1
touch /tmp/session_test_22323.txt
# Tab 2
ls /tmp/session_test_22323.txt
# Doesn’t exist
Different containers. That’s established.
Here’s what I missed: the container doesn’t allocate when you create an artifact or run bash commands.
It allocates the moment you load the page.
Check the hostname in a fresh Claude.AI tab—before you’ve done anything:
echo $HOSTNAME
# runsc
That’s gVisor. Already running. Just waiting.
Across repeated tests in my environment, this behavior is consistent. Every page load. Every time.
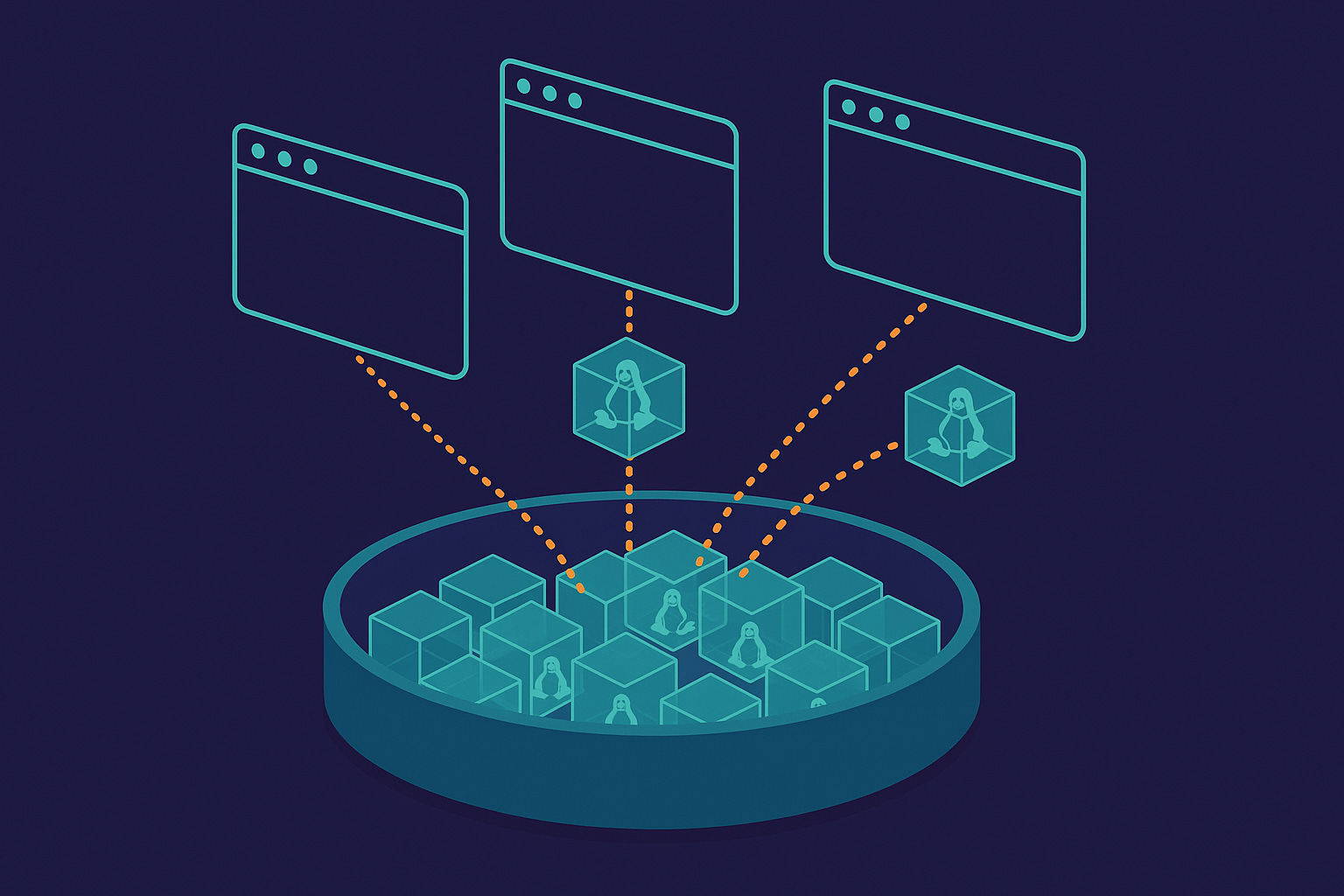
What’s Actually There (And What It Actually Means)
Every single Claude.AI tab I’ve tested loads with:
dpkg -l | wc -l
# 871 packages
du -sh /usr
# 4.8GB
free -h
# 9GB RAM allocated
Full Ubuntu environment. Complete with git, development tools, the works.
Not “if you use computer features.” Not “when you create artifacts.”
On page load.
But here’s where I initially got the implications wrong.
What gVisor Actually Is (Not What I First Assumed)
When you see HOSTNAME=runsc and free -h showing 9GB, it’s natural to think: “Each tab gets a dedicated VM with 9GB RAM and a full Ubuntu install.”
That’s not how gVisor works.
gVisor is a userspace kernel, not a hypervisor:
Intercepts syscalls from guest processes
Enforces isolation at the syscall boundary
Runs thousands of sandboxes per host
Shares most resources across sandboxes
The “9GB RAM” is a limit, not an allocation:
The sandbox can use up to 9GB if needed
Only pages actually touched consume real RAM
Most sessions touch a tiny fraction
The host only pays for what’s actually used
The “4.8GB filesystem” is shared:
Read-only Ubuntu base image mounted for thousands of sandboxes
Only per-sandbox writes go into small overlay layers
Shared image cached on each node
Most sessions never touch more than a subset
So when I initially modeled this as “VM-equivalent costs,” I was probably off by at least an order of magnitude.
The Scale Math (Revised Understanding)
Let me recalculate with a better understanding of the architecture.
Conservative user assumptions:
5M monthly active Claude.AI users
Average 3 tabs per session
10 sessions monthly
2 hours average per session
What actually happens: Every tab load = gVisor sandbox allocation 5M × 3 tabs × 10 sessions = 150M sandbox allocations monthly
Where my initial cost model went wrong:
I used VM pricing (~$0.06/hour) as a proxy. That assumes:
Dedicated compute resources per instance
Full memory allocation on provision
Traditional VM overhead
gVisor sandboxes are fundamentally different:
High-density multiplexing (thousands per host)
Memory allocated on-demand, not reserved
Shared base images across all instances
Aggressive overcommit strategies
Actual infrastructure costs are probably:
5-10x lower than VM-equivalent pricing
Still significant at scale
Driven by peak concurrent sandboxes, not total hours
Dependent on idle timeout policies
Even at 10x better economics than I initially modeled, you’re still looking at substantial infrastructure investment requirements. Just not the “barely breaking even on Pro users” story I first calculated.
The Design Logic (Still Valid)
From a technical perspective, the logic holds:
The problem: You can’t predict when someone will create an artifact or run bash commands. Wait to provision? Add latency. Users notice.
The solution: Pre-allocate on page load. Sandbox’s already there. When they create an artifact—instant.
Trade-off: Pay for sandboxes whether users need them or not. Most sessions I’ve observed never use computer features. You’re still carrying that cost.
The difference: That cost is lower than I initially thought, but the architectural choice remains the same.
The Warm Pool (Now Makes More Sense)
That 1-minute uptime I keep seeing? Fresh from the pool.
How it likely works:
Anthropic maintains warm pool of pre-initialized sandboxes
Base Ubuntu image already mounted
Page load grabs one, adds overlay filesystem
Associates with your browser session
Returns to pool after timeout
Why there’s no provisioning latency:
Pool already running
Just binding + overlay setup
Normal page load times
Sandbox ready when needed
Why this is still expensive (but sustainable): With gVisor’s density, you can run thousands of sandboxes per host. But you still need:
Enough hosts for peak concurrent sessions
Warm pool sized for typical tab patterns
Infrastructure to handle burst traffic
The absolute numbers are lower than VM math suggests. The architectural complexity and scale requirements remain.
The Unit Economics Question (Revised)
Look at this from Anthropic’s perspective with better cost assumptions.
If actual sandbox costs are 5-10x lower than VM pricing:
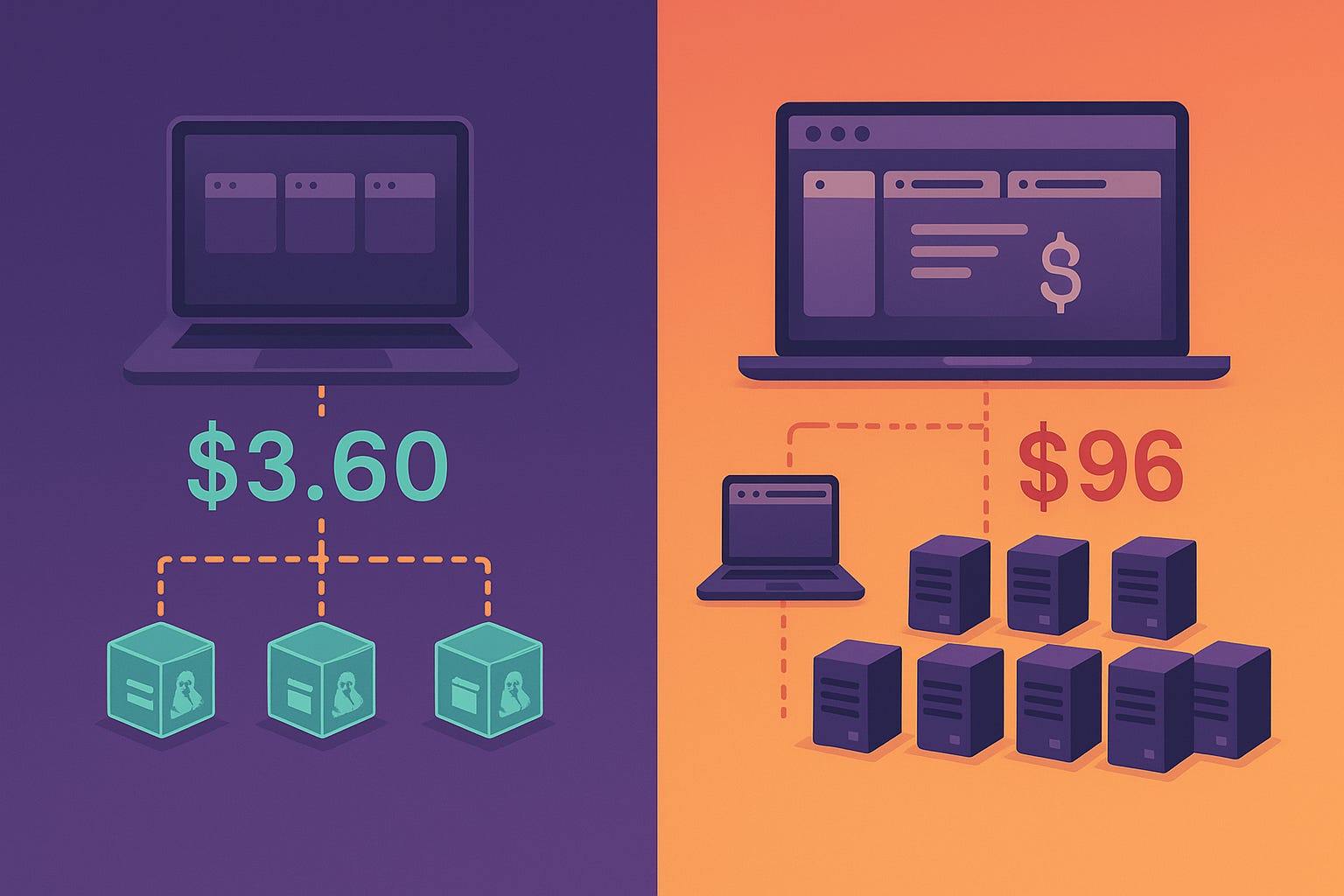
Pro user at $20/month:
Opens 30 tabs across 10 sessions
Each tab = 2 hours of sandbox time
Container costs: $0.36-0.72 (not $3.60)
Plus LLM inference: $8-12
Total cost: $8.36-12.72
Margins look healthier. Still tight for power users.
Power users:
10+ tabs simultaneously
All-day sessions
Multiple daily sessions
Even at 10x better economics: 10 tabs × 8 hours × $0.006-0.012 = $0.48-0.96 per session
20 sessions monthly: $9.60-19.20 in container costs (vs. $96 in my initial model)
Free tier users: Still subsidized. Just not as dramatically.
Why This Still Explains August
The architecture helps explain behaviors I observed, even with revised cost understanding:
Scaling challenges:
Demand surge
Each user = multiple concurrent sandboxes
Pool capacity constraints
Coordination across hosts
Rate limiting context: Not just LLM tokens. Sandbox capacity matters. High-density multiplexing has limits.
Infrastructure investment rationale: Even with better-than-VM economics, owned infrastructure makes sense:
Optimize for this specific workload
Custom gVisor configurations
Eliminate cloud provider margins
Better control over density and overcommit
The $50B investment still makes strategic sense. The immediate economic pressure just isn’t as severe as I first calculated.
What Other Chat Interfaces Do
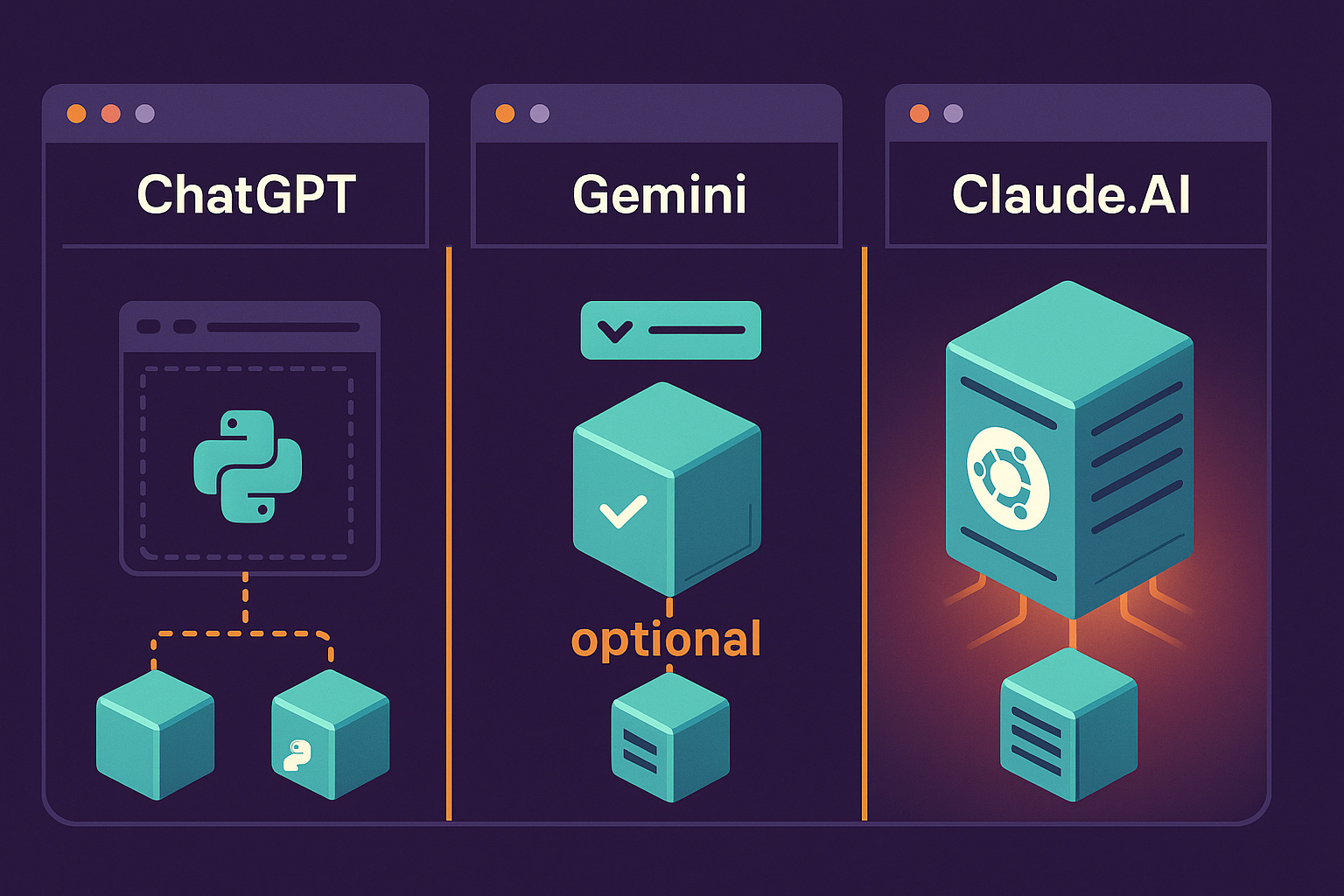
ChatGPT: Code interpreter runs in sandboxed Python (Docker containers). Documentation suggests persistent sessions tied to chat conversations rather than page loads, but OpenAI hasn’t published specific provisioning details.
Gemini: Similar Python sandbox approach. Code execution is an optional feature that can be enabled via API or CLI flags, suggesting on-demand provisioning, though Google hasn’t detailed the exact architecture.
Claude.AI: Full gVisor sandbox with Ubuntu environment. On page load. Whether you use it or not.
The capability difference remains significant. The cost differential is smaller than I initially thought, but the architectural complexity gap is real.
The Architecture Trade-Off (Still Stands)
Anthropic made a choice:
Option A: Provision on-demand
Lower cost (only pay when used)
Adds latency (users wait for provision)
Simpler infrastructure
Option B: Pre-allocate on page load
Higher cost (pay whether used or not)
No latency (already there)
More complex infrastructure
They picked B. The bet on experience over cost efficiency remains.
The actual cost premium is probably smaller than VM math suggests. The infrastructure complexity and engineering investment required is just as high.
What I Got Wrong (And Right)
What the testing showed accurately:
gVisor sandboxes allocated on page load
Separate isolation per tab
Full Ubuntu environment available
Zero-latency artifact/bash execution
What I initially misunderstood:
Sandbox costs ≠ VM costs
“9GB RAM” is a limit, not an allocation
Filesystem is shared, not per-instance
Density changes economics dramatically
What remains true:
This architecture is more complex than competitors
Pre-allocation strategy requires more infrastructure
Most users never touch container features
Scale drives need for vertical integration
The Revised Bottom Line
Based on repeated testing in my environment, every Claude.AI tab you open gets a gVisor sandbox with a full Ubuntu environment.
Not when you use computer features. On page load.
The economics (revised understanding):
Still significant infrastructure investment
Probably 5-10x better than my initial VM-based modeling
Driven by peak concurrency and warm pool sizing
Requires sophisticated resource management
This gives you capabilities no other chat interface provides. Complete isolation. Real development environment. Zero latency when you need it.
My initial cost estimates were probably wrong by an order of magnitude. The architectural sophistication and strategic investment requirements remain accurate.
My working theory: Anthropic prioritized capability and UX, betting on gVisor’s density to make the economics work while still requiring substantial infrastructure investment for vertical integration benefits.
The question isn’t whether the architecture is sustainable—it probably is. The question is whether the capability advantage justifies the infrastructure complexity.
Every time you load a Claude.AI page, you’re triggering a sandbox allocation. The cost is lower than I first calculated. The architectural commitment is just as high.
I’m Bob Matsuoka, writing about agentic coding and AI-powered development at HyperDev. For more infrastructure insights, read my analysis of multi-agent orchestration costs or my deep dive into AI development tool economics.