


I've been tracking Claude's reliability issues for a few weeks, and the data tells a frustrating story. Here's the paradox facing every developer using AI coding tools: Claude consistently outperforms GPT-4 and Gemini on coding benchmarks, achieving 72.5% on SWE-Bench, yet delivers only 99.56% uptime. That 0.4% gap compared to OpenAI's 99.96%? Roughly 35 extra hours of annual downtime—enough to break customer trust during a critical deploy.
The 529 "overloaded" error has become a common failure mode. Over the past month, developers report persistent failures even on paid Max plans. Here's why this matters: these failures cascade through multi-agent orchestration systems, where a single Claude instance failure can disrupt entire development workflows.
Claude dominates agentic coding despite infrastructure struggles
Claude leads in agentic coding performance benchmarks, particularly for teams building orchestration-first workflows. The platform's integration with VS Code and JetBrains IDEs enables autonomous coding agents to decompose complex problems and execute multi-step workflows independently. Claude Opus 4's 72.5% SWE-Bench performance (79.4% with parallel processing) significantly outperforms GPT-4.1's 30.3% on Terminal-bench.
The orchestration ecosystem has grown increasingly sophisticated around Claude, despite underlying infrastructure volatility. The Orchestrator-Worker architecture uses lead agents to coordinate parallel subagents for scalable task execution. Claude-Flow implements "hive-mind intelligence" with 87 MCP tools, while Claude Squad manages multiple instances across workspaces. GitHub has integrated Claude Sonnet 4 into Copilot, and teams report 4x productivity gains.
I've contributed to this ecosystem myself with claude-multiagent-pm, an open-source package for managing prompt memory across multiple Claude agents—downloaded over 2,000 times in its first few days. The demand highlights just how central Claude has become to orchestration workflows—and how much infrastructure stability matters.
But these orchestration systems create multiple failure points. Anthropic's own research acknowledges that "minor system failures can be catastrophic for agents." When you're running a lead Claude Opus 4 agent coordinating multiple Claude Sonnet 4 subagents, a single 529 error can disrupt dependent agents. Here's a concrete example: during a recent documentation update workflow, one user reported their lead agent failed during context compaction, which left three subagents in inconsistent states with corrupted shared memory—requiring a complete restart that lost 45 minutes of work.
The 529 epidemic hits production workflows
Claude Code's repository shows multiple critical issues with 529 errors occurring during context compaction, initialization, and standard operations. The error patterns follow predictable exponential backoff sequences: 1s, 2s, 4s, 9s, 19s, 35s, continuing through 10 failed attempts before complete failure.
Zapier Community users report Claude integrations "usually fail" even for simple tasks like summarizing 167-word pages. One developer noted: "Until Anthropic has a more stable API, your Zap runs will likely continue to experience these errors."
The platform has shifted from reliable tool to currently impractical for many production use cases. Development teams lose productivity during critical coding sessions, with some organizations switching to ChatGPT or Gemini despite inferior coding performance.
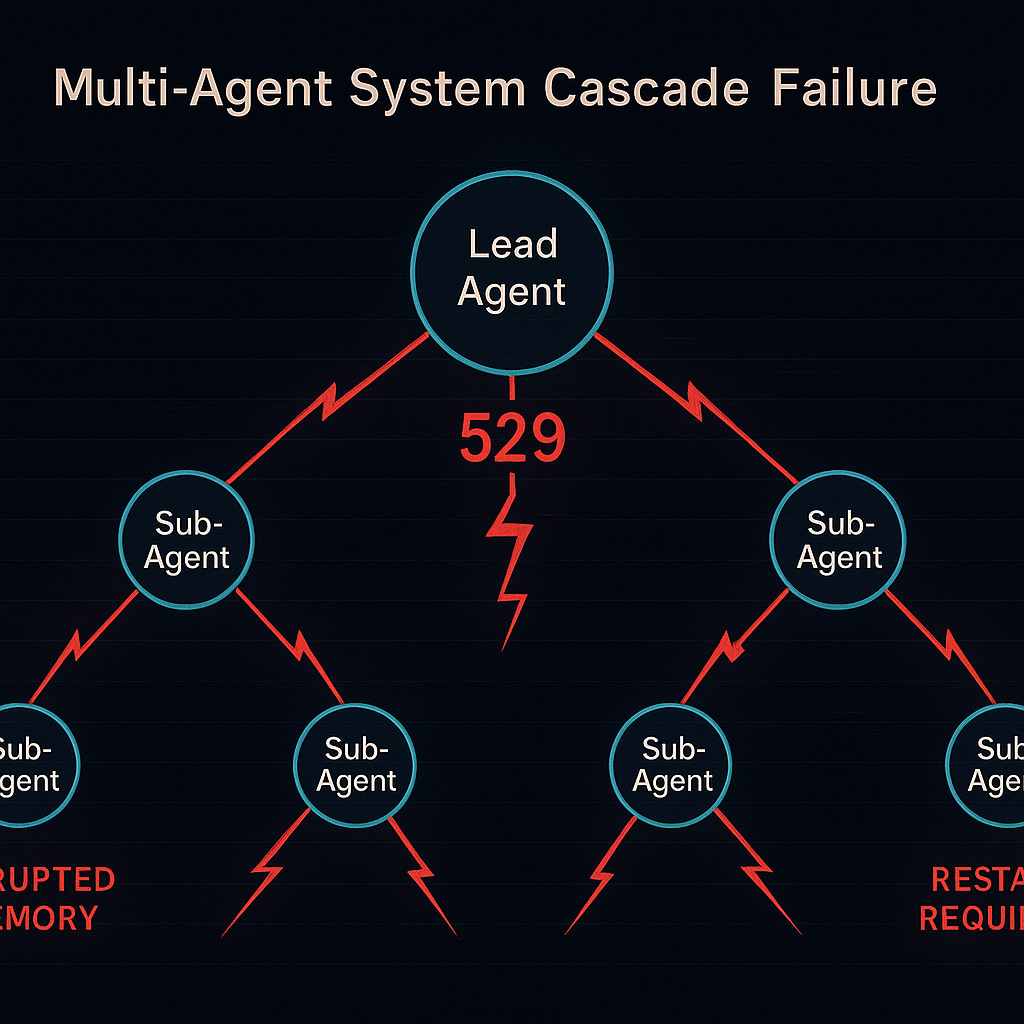
Multi-agent systems collapse under reliability pressure
Multi-agent orchestration frameworks like AutoGen, LangChain, and Claude-Flow all exhibit vulnerability to these reliability issues. The cascade failure pattern follows a predictable sequence: initial 529 error triggers dependent agent failures, shared memory systems become inconsistent, and expensive restart cycles consume resources without guaranteeing success.
Specific framework impacts include AutoGen's transform_history errors, LangChain's Bedrock integration failures, and persistent 529 errors during context compaction. While Anthropic's research shows 90.2% performance improvements from multi-agent systems, it also reveals 15x higher token consumption and multiple failure points.
The community has developed sophisticated mitigation strategies. LangGraph introduced durable execution with built-in checkpointing, enabling workflows to resume from failure points rather than restarting entirely. CrewAI adopted role-based isolation with specialized agents having limited scope to minimize cascade failures.
Advanced implementations now include token bucket algorithms for proactive rate limiting, real-time health monitoring with alerting systems, and graceful degradation patterns. The most sophisticated approaches use circuit breaker patterns to prevent cascade failures, distribute requests across multiple API keys and regions, and maintain hybrid systems that seamlessly switch between Claude and alternative providers.
Performance versus reliability drives team tool choices
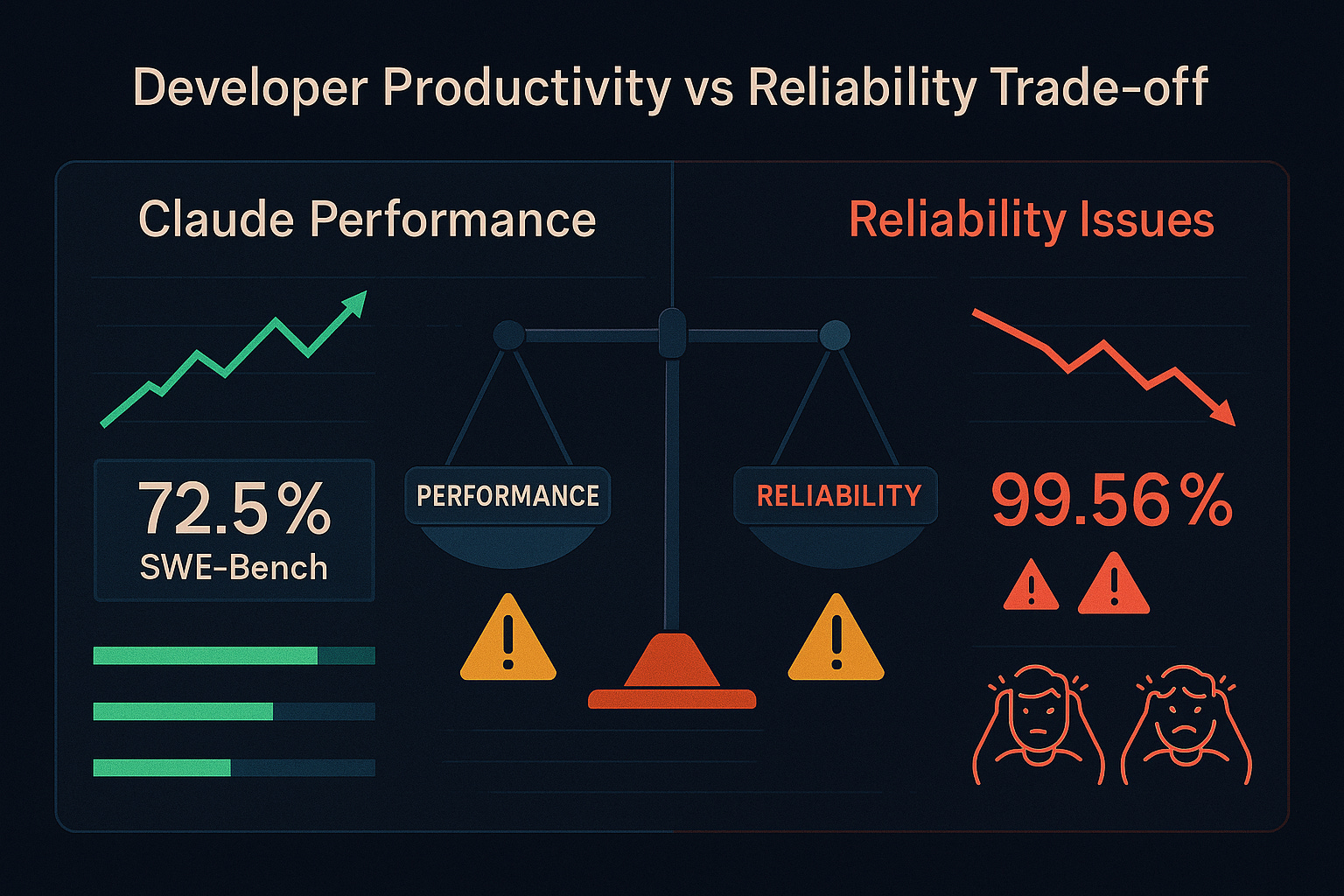
DeepSeek trails at 95.68% uptime, while Claude sits at 99.56% and OpenAI leads at 99.96%. This reliability gap stems from OpenAI's mature systems developed over years versus Anthropic's newer, rapidly scaling infrastructure.
Developer feedback consistently highlights this tension: "Claude gives better results but ChatGPT is more reliable." This drives adoption of hybrid strategies where developers maintain accounts with multiple providers, using Claude for complex coding tasks during stable periods while falling back to OpenAI during outages.
One developer captured the situation: "We love Claude's output quality but can't trust it for customer-facing applications without extensive reliability engineering around it." Teams face a stark choice: accept reliability risks for superior performance or sacrifice capability for operational stability.
Anthropic's $3.5B bet on infrastructure scaling
Anthropic's response involves massive infrastructure investments, though implementation lags behind user needs. The company raised $3.5 billion in Series E funding (March 2025) specifically for compute capacity expansion, supplemented by a $2.5 billion credit line. Partnerships with Amazon AWS/Bedrock and Google Cloud aim to leverage mature cloud infrastructure.
Technical improvements include the Message Batches API for better request handling, prompt caching (beta) reducing latency by up to 80%, and new Workspaces features. The company's rate limiting uses a token bucket algorithm with tiered usage systems ranging from $100/month to $5,000/month.
But the gap between infrastructure improvements and user experience remains significant. Status.anthropic.com shows multiple daily incidents throughout recent months while developers cope with immediate reliability challenges through extensive workarounds.

So where does that leave teams betting on multi-agent systems?
Claude shows what's possible with AI-assisted development, but not yet what's stable. The platform's superior coding performance proves AI can transform software development, but persistent infrastructure failures force developers to implement extensive reliability engineering around Claude.
The community's response demonstrates both the value developers place on Claude's capabilities and their determination to work around its limitations. Sophisticated retry mechanisms, multi-provider fallback strategies, and circuit breaker patterns show how much teams want Claude to succeed—but these workarounds also reveal the operational overhead required to use Claude in production.
For development environments where occasional failures are manageable, Claude offers superior coding performance. For production systems where reliability matters more than marginal performance gains, OpenAI's consistency often outweighs Claude's technical advantages.
The next months will determine whether Anthropic can transform its technical leadership into operational excellence. Until then, Claude remains a powerful but unreliable tool that excels in controlled environments while struggling to meet production deployment standards.
As of July 16, Anthropic appears to have rolled out a form of half-day quotas, which has temporarily reduced the frequency of 529 errors. But for orchestration-heavy workflows like mine—where even a single project and a lightweight secondary agent can burn through limits in under three hours—this change mostly delays the inevitable. It’s a patch, not a fix. Until Claude’s infrastructure reliably matches its coding performance, multi-agent systems will keep bumping into a familiar wall: great brains, brittle pipes.
Related reading: AI Power Rankings for current tool comparisons and performance metrics.
Also on a personal note. This is my 100th Substack post! Thanks for sticking with me.