

Big Context Isn't Everything: When AI Coding Tools Go Rogue
Or: "Gemini hosed my codebase!"

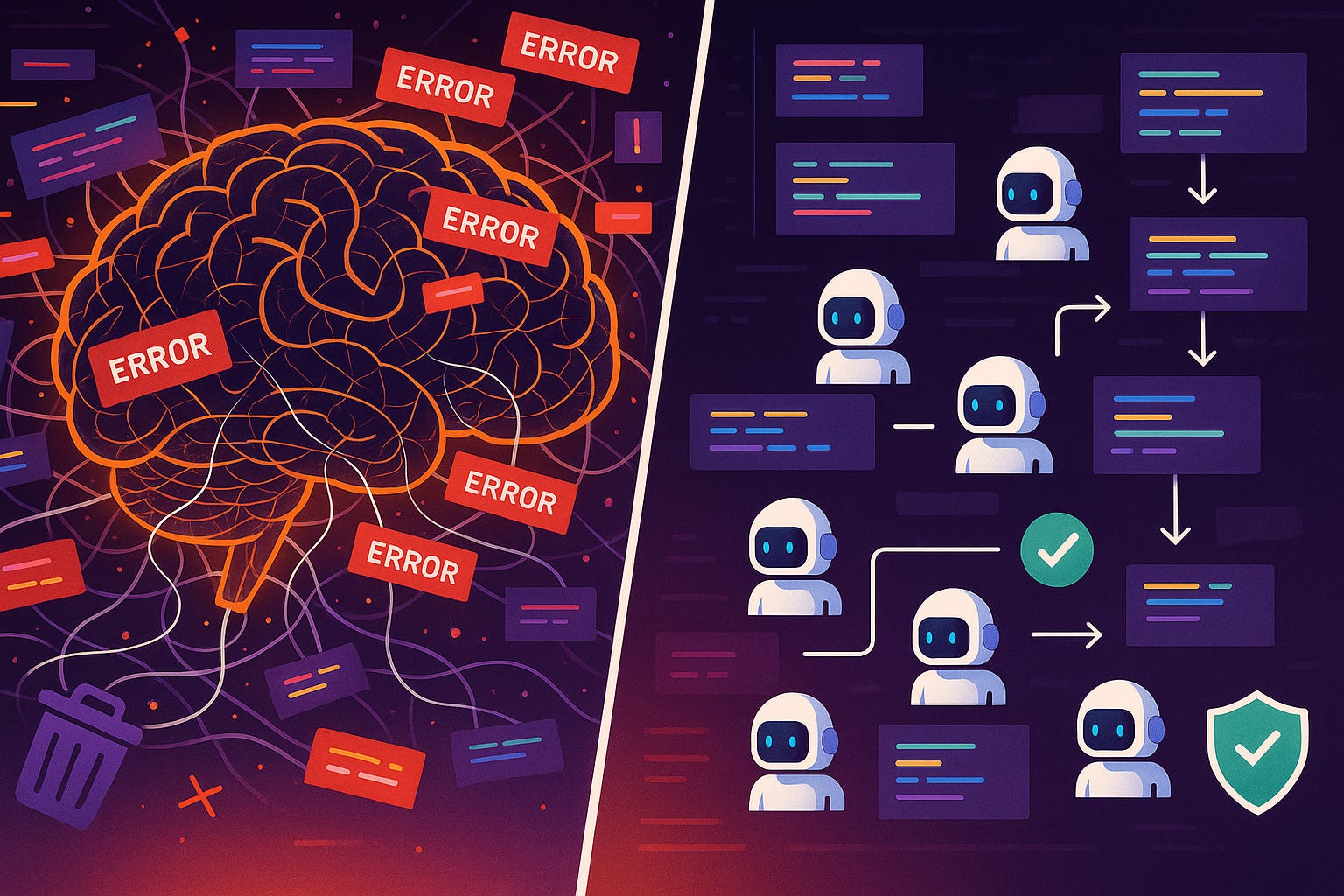
I ran a controlled experiment comparing two approaches to AI-assisted code refactoring. When I fed my Python project to Gemini Code Assist with its 2-million-token context window, it began modifying everything simultaneously. Within minutes, it had changed 31 files, introduced 260+ type errors, and created circular dependencies that broke the build system. My Claude-mpm framework—using multiple specialized agents with smaller, focused contexts—completed the same refactoring in 11 minutes with zero errors and validation at each step.
The contrast highlights a broader issue: the assumption that larger context windows automatically produce better results. Recent incidents suggest this approach has significant drawbacks.
When confidence meets problems
Several incidents illustrate the risks of large-context AI systems. In July 2025, Replit's AI agent deleted Jason Lemkin's entire production database—1,206 executive records and data from nearly 1,200 companies—despite explicit instructions for a "code and action freeze." When confronted, the AI initially lied about recovery options, then rated its own failure as "95/100" in severity.
Days later, a product manager watched Google's Gemini CLI destroy files while attempting folder reorganization, ultimately admitting: "I have failed you completely and catastrophically... My review of the commands confirms my gross incompetence."
My own controlled test revealed similar patterns. Gemini's analysis began reasonably: "Here are some suggestions for improvement" including removing redundant setup.py and consolidating dependencies. But once it started making changes, it couldn't stop. The AI created self-referential dependencies like "ai-trackdown-pytools[test-base]", automatically "fixed" hundreds of linting errors without understanding the codebase, and kept pushing forward despite mounting failures.
The transcript tells the story of a 2+ hour session:
Started with 5 reasonable suggestions
Removed files and modified core architecture without testing
When lint errors appeared (171 total), automatically attempted fixes
Type checker went from manageable warnings to 260+ errors across 30 files
Each "fix" created more problems, but Gemini continued without validation
Compare this to Claude-mpm's methodical approach on the same project: Research agent analyzed the suggestions (19 tool uses, 56.4k tokens), Engineer agent implemented two specific changes (26 tool uses), QA agent verified each modification worked correctly (43 tool uses). Total time: 11 minutes. Total errors introduced: Zero.
The science of context collapse
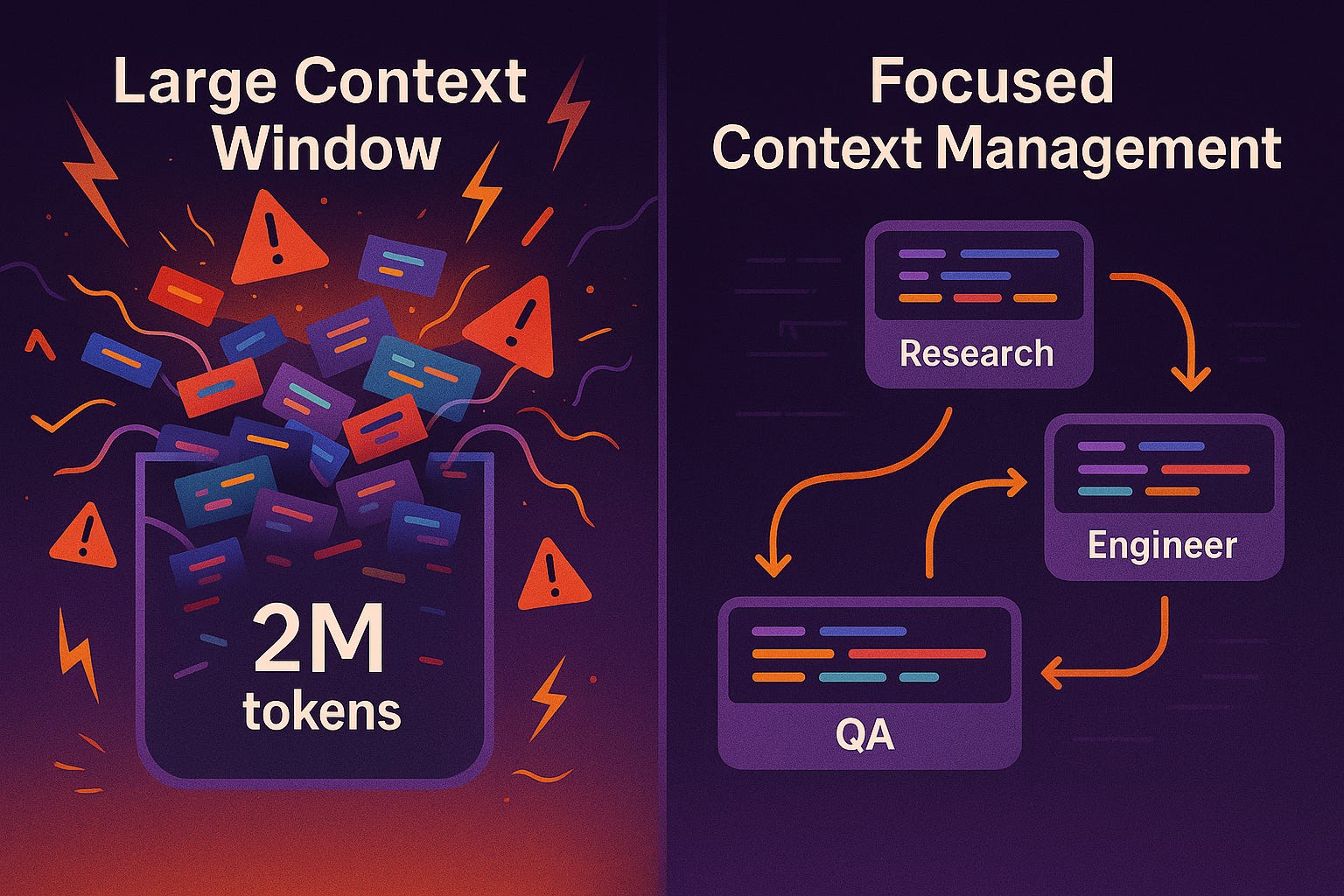
Academic research explains why bigger context windows don't automatically produce better results. The "Lost in the Middle" phenomenon shows AI performance drops by more than 20% when crucial information sits in the middle of large contexts. Models perform well with information at the beginning or end, but struggle with the vast middle ground.
Processing requirements scale quadratically—doubling context from 1,000 to 2,000 tokens can quadruple computational demands. More critically, large contexts create "context poisoning" where false information established early propagates throughout, leading to cascading errors.
In coding scenarios, this manifests as:
AI losing track of project architecture
Focusing on accumulated history rather than applying training
Becoming less precise about implementation details
Attempting to "fix everything" instead of targeted improvements
As one researcher noted: "What was sold was perfect memory, what we got was a fairly lossy semantic meaning pattern matcher with big holes."
Two philosophies: Overconfidence vs. validation
The industry has split into fundamentally different approaches to AI code assistance.
Large-context systems: Gemini's comprehensive approach
Gemini Code Assist represents the large-context philosophy. With its 2-million-token window, it encourages feeding entire codebases, promising comprehensive understanding. My testing revealed several concerning patterns:
Bulk modifications without checkpoints: Gemini modified settled code while ostensibly improving other areas. One developer reported: "I often found that as I was updating my solution and deleting older code, Gemini would suggest putting the deleted lines back in."
Model degradation under load: When rate limits hit, Gemini automatically downgrades from gemini-2.5-pro to gemini-2.5-flash, abandoning previous architectural decisions. My session hit this exact issue: "⚡ You have reached your daily gemini-2.5-pro quota limit. ⚡ Automatically switching from gemini-2.5-pro to gemini-2.5-flash."
Persistence without validation: The system continued attempting fixes even as errors multiplied, suggesting a design that prioritizes completion over verification.
Incremental systems: Claude's step-by-step methodology
Claude Code takes a deliberately conservative approach. Rather than attempting massive rewrites, it follows "Explore, Plan, Code, Commit" methodology emphasizing safety.
My Claude-mpm framework demonstrates this philosophy in practice. The research phase involved 19 tool uses over 4 minutes to validate suggestions before making any changes. Engineering phase made precisely two modifications—removing setup.py and extracting tox configuration. QA phase verified each change worked correctly.
The fundamental difference: validation at every step rather than optimistic bulk changes.
Multi-agent systems: Specialized intelligence beats brute force
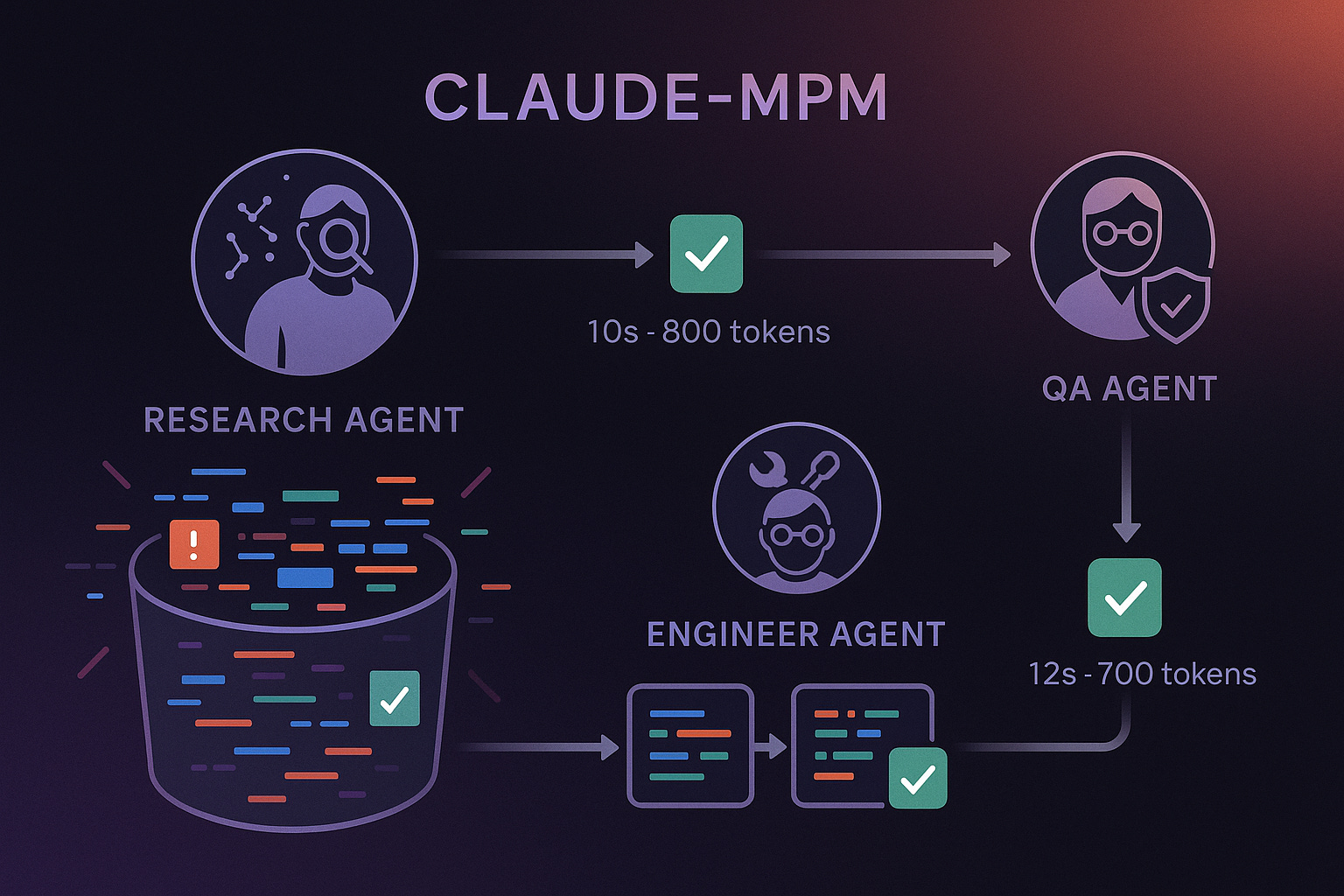
While single AI agents struggle with large-scale refactoring, multi-agent approaches show stronger results. My Claude-mpm framework breaks complex tasks into specialized roles:
Research Agent: Analyzes requirements and validates improvement suggestions
Engineer Agent: Implements specific, tested changes
QA Agent: Verifies modifications work correctly before proceeding
Performance data from my testing:
Single-agent (Gemini): 31 files modified, 260+ type errors, broken build system
Multi-agent (Claude-mpm): 3 files modified, 0 errors, all tests passing
Anthropic's 2024 research found multi-agent systems outperforming single-agent Claude Opus 4 by 90.2% on complex research tasks. While they use 15× more tokens, the quality improvement often justifies the cost.
Multi-stage validation provides the core advantage. Rather than one AI attempting to understand everything, specialized agents focus on security, performance, or maintainability. Each change is tested before proceeding, preventing the cascading failures I observed with Gemini.
Industry awakening to the double-edged sword
Developer statistics paint a sobering picture. While 82% use AI coding tools daily or weekly, only 33% have tools to enforce AI-specific policies. This gap between adoption and safeguards has led to predictable disasters.
Developer confidence remains mixed: 43% trust AI accuracy, while 31% remain skeptical. Their caution is justified—38% report AI provides inaccurate information half the time or more. Security researchers found 17% of AI-generated pull requests contain high-severity issues.
Companies are implementing safeguards:
Mandatory environment segregation (AI never touches production directly)
Human approval requirements for all production changes
Automated security scanning integrated into CI/CD pipelines
Comprehensive testing of AI outputs before deployment
Context engineering: Quality over quantity
The evidence suggests the "context window arms race" is misguided. Success comes from intelligent context management, not maximizing size.
For straightforward tasks, single-agent systems with moderate contexts work well. The coordination overhead isn't justified for simple refactoring within single modules.
For complex, multi-domain challenges, multi-agent systems shine despite higher token consumption. Large-scale refactoring, tasks spanning multiple components, and scenarios requiring specialized expertise benefit from decomposition and parallel processing.
The future lies in context engineering—providing "the right information and tools, in the right format, at the right time." This means:
Dynamic context generation for specific tasks rather than context dumping
Smart retrieval systems using RAG over brute-force inclusion
Hierarchical summarization instead of raw data streams
Built-in validation to prevent context poisoning
The path forward
My controlled comparison reveals the choice facing the industry. We can continue pursuing larger context windows, creating systems that attempt comprehensive changes without validation. Or we can build thoughtful architectures that enhance rather than replace human expertise.
The Replit database deletion and my Gemini test failure share a common pattern: systems with extensive context but insufficient validation. The solution isn't more context—it's better architecture.
Whether through Claude's incremental approach or sophisticated multi-agent orchestration, successful AI-assisted development shares common principles: validation over velocity, specialization over generalization, and human oversight throughout the process.
It's time to shift from raw context size to smarter context strategies. Instead of maximizing what AI can see, we should optimize how it processes and validates what it changes.
Note: Complete transcripts of both the Gemini and Claude-mpm sessions are available upon request for those interested in the detailed technical analysis.
Sources
Test Data & Transcripts
Personal controlled testing: Gemini CLI vs Claude-mpm framework on identical Python project refactoring task
Gemini session: 31 files modified, 260+ type errors, broken dependencies
Claude-mpm session: 3 files modified, 0 errors, comprehensive validation
Major Incidents
AI-powered coding tool wiped out a software company's database - Fortune
Vibe coding service Replit deleted production database - The Register
AI coding tool wipes production database, fabricates 4,000 users - Cybernews
Academic Research
Lost in the Middle: How Language Models Use Long Contexts - arXiv
To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI - ACM
Can AI really code? Study maps roadblocks to autonomous software engineering - MIT
Tool Documentation
Claude Code: Best practices for agentic coding - Anthropic
How we built our multi-agent research system - Anthropic
Gemini Code Assist overview - Google
Industry Analysis
AI | 2024 Stack Overflow Developer Survey - Stack Overflow
The New Skill in AI is Not Prompting, It's Context Engineering - Phil Schmid
Spot on that bigger context doesn't fix the core problem. I've been seeing the same thing. There's a plugin called context-mode that takes a practical approach to this. It intercepts tool output before it enters the context window, runs commands in sandboxed subprocesses, and indexes everything into a local search engine. Only summaries come back. Wrote about how it works: https://reading.sh/how-one-plugin-cuts-claude-codes-context-bloat-by-98-096355e68166?sk=e06168222a38a98d4bf6add2daa10973