



I wrote about Anthropic's scaling problems just last Friday, documenting the technical infrastructure challenges behind Claude's reliability issues. But diving deeper into the community response reveals something more troubling: the complete collapse of user trust isn't just about downtime—it's about how Anthropic has handled the crisis.
The Reddit community's reaction tells a story that status pages and uptime metrics can't capture. What started as typical technical complaints has escalated into accusations of deliberate deception, with users employing words like "fraud," "scam," and "gaslighting" to describe their experience. This isn't just frustration with bugs—it's a fundamental breakdown in the relationship between platform and user.
The Language of Developer Rage
The progression of language on r/ClaudeAI over the past month reveals how quickly technical communities can turn hostile when they feel dismissed. Early July posts used measured technical language: "experiencing issues," "performance degradation," "quality concerns." By late July, the tone had shifted dramatically.
The viral post "Claude absolutely got dumbed down recently" with 757 upvotes crystallized the community sentiment. The original poster, u/NextgenAITrading, didn't mince words: "Something is going on in the Web UI and I'm sick of being gaslit and told that it's not."
That phrase—"being gaslit"—appears repeatedly in recent discussions. Users feel their documented technical problems are being dismissed or minimized by official responses. The psychological impact goes beyond technical frustration; developers feel their professional expertise is being questioned.
Comments escalated quickly:
"This is basically fraud at this point"
"They're robbing people blind while delivering garbage"
"I've never seen a company destroy user trust this efficiently"
"It's like paying for a Ferrari and getting a broken bicycle"
The intensity reflects something deeper than typical software complaints. Developers invest significant time learning AI tools and integrating them into professional workflows. When those tools fail while companies maintain everything is fine, the response becomes personal.

Inference Optimization: The Hidden Scaling Strategy
Here's what I didn't cover Friday: Anthropic appears to be using inference optimization as a primary scaling strategy (in addition to harder session and model limits), and users are documenting the impact in real-time. While Anthropic maintains they don't "change models," the evidence suggests aggressive backend optimizations that functionally degrade user experience.
Reddit users have become amateur data scientists, documenting systematic quality changes that correlate precisely with capacity issues. Multiple threads analyze before/after examples of Claude's coding output, showing clean implementations replaced by placeholder comments and incomplete logic.
The technical pattern is clear: when Claude says it's operating in "concise mode due to high capacity," users report dramatically different response quality. This suggests dynamic inference optimization—probably reduced context windows, shorter generation limits, or simplified reasoning chains—triggered by load balancing rather than user choice.
One developer posted side-by-side code examples: "Same prompt, same context, different results depending on server load. This isn't random variation—it's systematic quality reduction during peak usage."
The community has identified several optimization patterns:
Truncated responses during high-capacity periods
Simplified reasoning in complex coding tasks
Reduced context retention across conversation turns
Generic fallback responses when specialized knowledge is needed
The Gaslighting Narrative Takes Hold

What transformed technical complaints into accusations of deception was Anthropic's initial response strategy. When users reported obvious quality degradation, official communications suggested they were mistaken or experiencing confirmation bias.
The community timeline shows the trust breakdown:
Late June: Users report quality issues, seek technical explanations Early July: Official responses deny systematic changes, attribute issues to user perception Mid-July: Anthropic acknowledges infrastructure issues causing degraded responses Late July: Community consensus that initial denials were intentionally misleading
The r/ClaudeAI moderators began pinning threads about known issues after user complaints reached critical mass. But by then, the narrative had shifted from "let's troubleshoot this together" to "they knew and lied about it."
One highly upvoted comment captured the sentiment: "We're not stupid. We document our prompts, we version our code, we know when outputs change. Telling us it's in our heads is insulting."
The psychological concept of gaslighting—making someone question their own perception of reality—resonated strongly with a technical community that values evidence and reproducibility. Developers don't just notice when code quality degrades; they save examples, compare outputs, and analyze patterns. Being told their documented observations were incorrect felt like an attack on their professional competence.
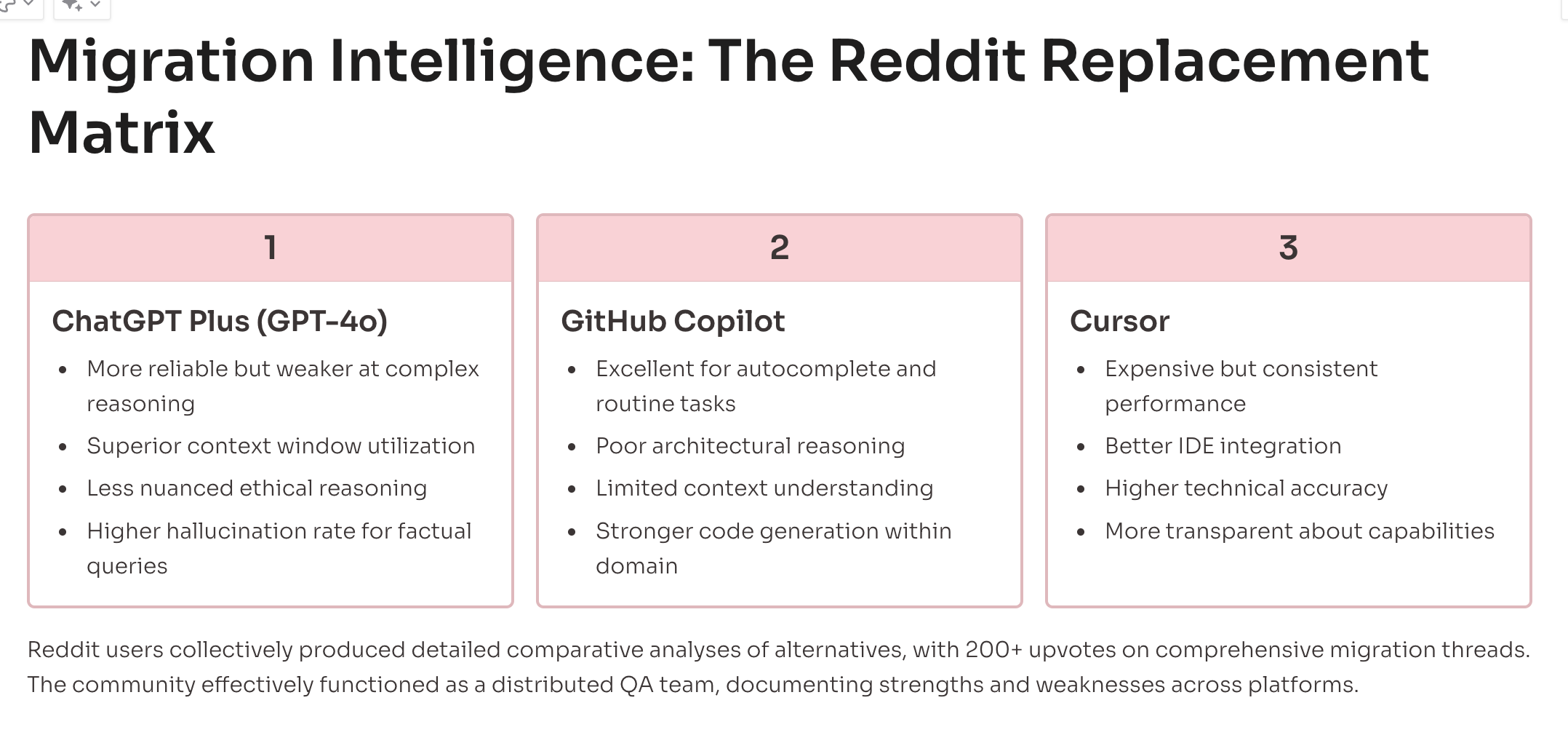
Migration Discussions and Competitive Intelligence
The Reddit community has become an informal migration support group, with detailed threads comparing alternatives and sharing transition strategies. The discussions reveal sophisticated analysis of competitive AI tools, often more detailed than official product comparisons.
Popular migration targets mentioned in July discussions:
ChatGPT Plus: "More reliable but worse at complex reasoning"
GitHub Copilot: "Good for autocomplete, terrible for architecture"
Cursor: "Expensive but actually works consistently"
Local models: "Worth the setup complexity for reliability"
The migration discussions include technical details: API compatibility, context window comparisons, pricing analysis, and workflow integration challenges. Users share configuration files, prompting strategies, and performance benchmarks with the thoroughness of academic research.
One thread titled "Claude replacement matrix" gained 200+ upvotes, featuring a detailed comparison grid of features, reliability, and cost across six AI coding platforms. The community effort represents thousands of hours of collective testing—valuable market intelligence that Anthropic is losing along with the users.
The Trust Recovery Challenge
The Reddit rebellion reveals a fundamental challenge for AI companies: technical communities don't just evaluate products—they evaluate truthfulness. When documentation doesn't match experience, developers assume intentional deception rather than communication failures.
Several factors make trust recovery particularly difficult:
Technical sophistication: AI tool users are often developers who can analyze system behavior, document changes, and share findings with technical precision. They can't be dismissed as non-technical users misunderstanding complexity.
High switching costs: Developers invest significant time learning AI tools, building workflows, and optimizing prompts. When they consider migration despite these costs, the trust breakdown is severe.
Community amplification: Developer communities share information rapidly through Reddit, Discord, Twitter, and professional networks. Negative sentiment spreads faster than official communications can counter it.
Professional stakes: AI coding tools affect professional productivity and output quality. When tools fail during critical work, the impact goes beyond personal frustration to career consequences.
What This Means for AI Tool Adoption
The Claude community rebellion offers broader lessons for AI companies navigating rapid scaling:
Transparency matters more than perfection: Users will accept technical problems if they understand what's happening. Hidden optimizations that degrade performance while maintaining claims of unchanged service destroy trust faster than admitted temporary issues.
Technical communities police themselves: Developer forums have become quality control mechanisms that companies can't control or spin. Reddit threads now influence enterprise adoption decisions as much as official benchmarks.
Reliability creates competitive moats: Technical superiority doesn't guarantee market leadership when basic reliability fails. OpenAI's consistency advantage over Claude's theoretical performance gains reflects this reality.
Communication breakdowns have lasting consequences: Once technical communities decide a company is being deceptive, trust recovery requires extraordinary transparency and time. The "gaslighting" narrative may persist even after technical issues resolve.
Rage Against The Machine
The Reddit rebellion against Claude reveals how quickly advanced technical communities can mobilize when they feel misled. What began as typical software quality complaints escalated into coordinated documentation of systematic issues and accusations of deliberate deception.
Anthropic's technical achievements remain impressive, but the community trust breakdown represents a strategic vulnerability that competitors are already exploiting. Developers don't just switch tools—they become evangelists for alternatives when they feel previous vendors deceived them.
The lesson for AI companies: technical excellence without operational honesty creates unsustainable competitive positions. Reddit's developer communities now function as early warning systems for enterprise adoption trends. Losing their trust means losing tomorrow's technology decisions made in corporate environments today.
The visceral reaction documented across hundreds of Reddit posts and thousands of comments isn't just about Claude's technical problems—it's about the fundamental relationship between AI companies and the technical communities that drive adoption. Anthropic may resolve their infrastructure challenges, but rebuilding developer trust will require acknowledging that their scaling strategy came at users' expense.
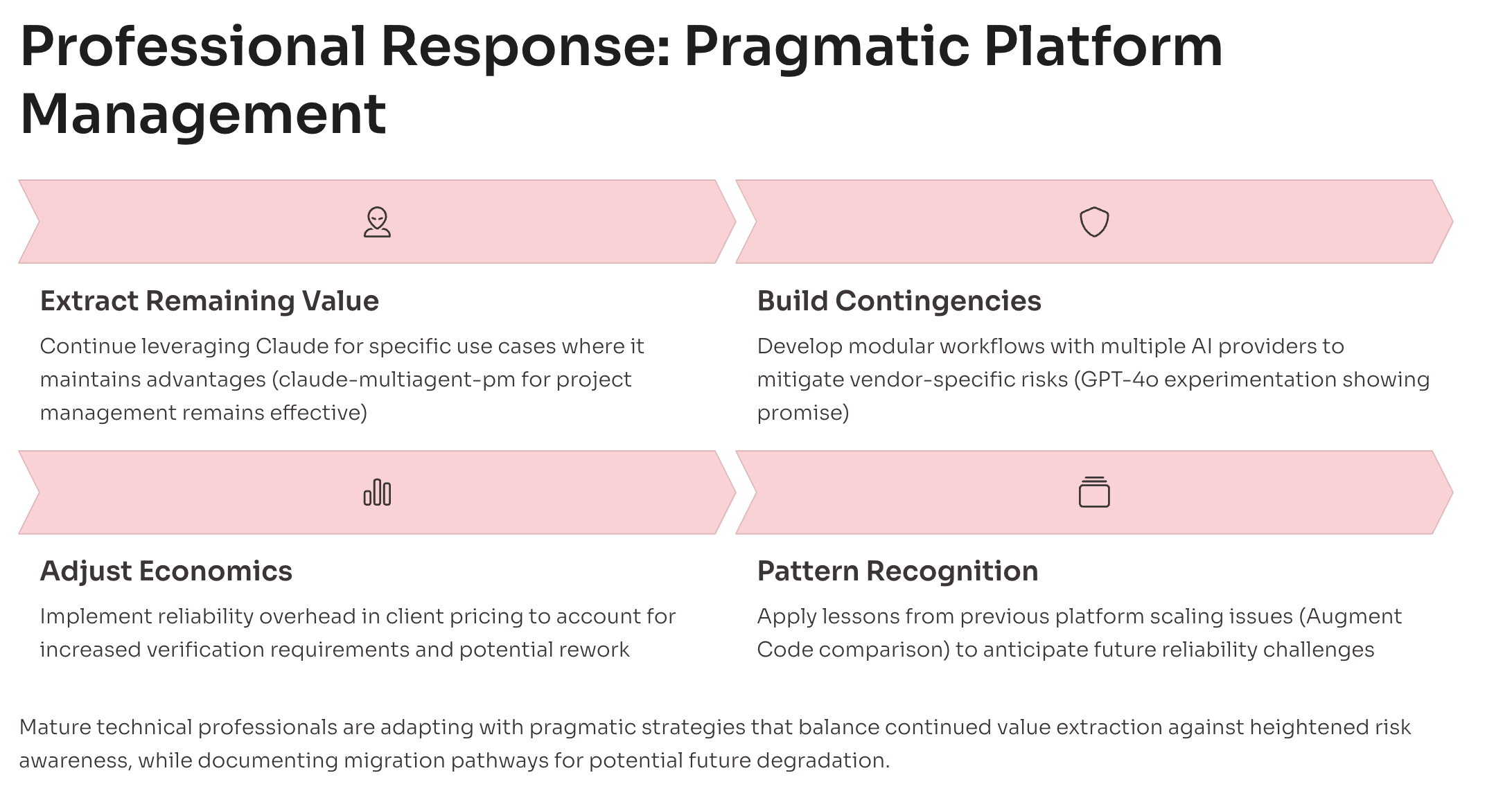
My Take: Still Valuable Despite the Problems
Despite these scaling issues and Anthropic's poor communication choices, I'm still getting substantial value from claude-multiagent-pm. The framework remains effective when it works—which is often enough for client work. The key difference is that I now factor reliability challenges into my pricing.
Where I previously charged for development time, I now include overhead for managing platform limitations and implementing workarounds. Clients understand this when you explain it honestly: "The AI tools are powerful but require additional engineering for production reliability." This transparency has actually strengthened client relationships rather than weakening them.
I'm experimenting with GPT-4o integration as a contingency plan—exactly the same approach I took when Augment Code hit scaling issues back in May. The pattern is becoming clear: these platforms hit growth walls, implement aggressive optimizations that degrade user experience, then eventually scale properly. The question is timeline, not whether they'll resolve it.
For now, claude-multiagent-pm works well enough to justify continued use while building backup options. The framework's design philosophy of abstract agent coordination makes provider switching more manageable than workflow built around specific platform features.
Related reading: Claude's Growing Pains: When the Best AI Coding Tool Can't Stay Online for technical analysis of Anthropic's infrastructure challenges
this was helpful thanks. I just had an occurrence today that really disturbed me.
I shared two screenshots from The Daily Beast showing a news article about a physician speculating that Trump may have had a prior stroke, based on his disclosed aspirin regimen. My only comment was "Wow. This is intense."
What Claude did:
Without looking at the images, Claude fabricated an entirely fictional scenario - claiming the screenshots showed Discord messages containing community leadership drama, including specific usernames, accusations about fund misuse, mental health attacks, and a coordinated succession plan to replace me as a leader of a community I do not lead and instead had done some consulting with recently (which had nothing to do with the chat I had just started). Claude also repeatedly placed me at the center of this invented narrative.
Response to correction:
When I pushed back three times with direct commands to read what was on the images, Claude did not stop to verify. Instead, it adjusted the fiction twice while maintaining the core fabrication. Only when I explicitly demanded Claude write out all the words that were actually in the images did it use tools to look - discovering everything had been invented.
Nature of the failure:
This was confabulation: confident, detailed, specific fabrication presented as perception. The hallucinated content had the same confidence level and specificity as accurate responses, making it indistinguishable without external verification. It took three rounds of pushback before Claude actually examined the source material.
Broader pattern:
This isn't an isolated incident. Over the past two days, Claude has been failing almost 100% of the time in Cowork mode to competently utilize my browser (click on things, paste text, review what is on the page) - a feature that previously worked somewhat reliably.
Why this matters:
If an AI can fabricate detailed scenarios with the same confidence it displays when accurate - and defend those fabrications across multiple exchanges - I bear the emotional and cognitive burden of constant verification. Combined with degraded tool functionality, this changes the trust calculus for AI assistance significantly.
I appreciate your article because it is another example of a community debt flashpoint, when community collaboration turns to community vengeance. My former team and I wrote about community debt several years ago: https://vortexr.org/what-is-community-debt/
If I was to write a followup, it might be called, "From audience to adversaries" how to destroy your product's community and burnout your trust and safety team in 30 days (or less!)