

AI vs Human Problem-Solving Shows Why Judgment Still Beats Probability
Or: The Dangers of Stochastic Engineering


TL;DR: Key Highlights
Thanks to Alex May and Jean Barmash for suggesting we add these quick-hit summaries to help busy developers get the core insights fast.
• The judgment gap is real: Experienced engineers solve problems through targeted analysis; AI uses probabilistic shotgun approaches that often work but miss root causes
• Speed vs effectiveness paradox: METR study shows experienced developers are 19% slower with AI tools despite feeling 20% faster—we're deceiving ourselves about current AI effectiveness
• Case study reality check: When debugging WordPress performance issues, Claude applied 7 optimizations achieving 98% improvement; human engineer Oswaldo made 3 targeted changes that fixed the actual bug
• AI excels in constrained spaces: Pattern-based tasks like test generation, boilerplate code, and API clients see 70% time savings; complex debugging and architecture decisions still require human judgment
• Economic implications: Teams need fewer junior developers but more senior architects; AI amplifies junior productivity while sometimes hindering expert-level work
• Practical workflow: Human defines architecture → AI implements → Human reviews → AI generates tests → Human validates. Checkpoints beat full autonomy
• Bottom line: AI is powerful pattern matching without judgment. Use it for mechanical coding tasks, reserve human expertise for decisions that actually matter
An experienced engineer will almost always write code better than AI in its current state. This isn't my pessimism about AI's future or a rejection of the new tools. It's a practical observation from the trenches, one that becomes crystal clear when you watch how differently humans and AI approach the same problem.
Let me share a cautionary tale that perfectly illustrates where we are with agentic coding in 2025. When code that pulled content from a WordPress blog was experiencing performance issues, two approaches emerged: Claude, representing state-of-the-art AI, and Oswaldo, an experienced engineer. The way each tackled the problem reveals fundamental truths about the current state of AI coding that every developer needs to understand.
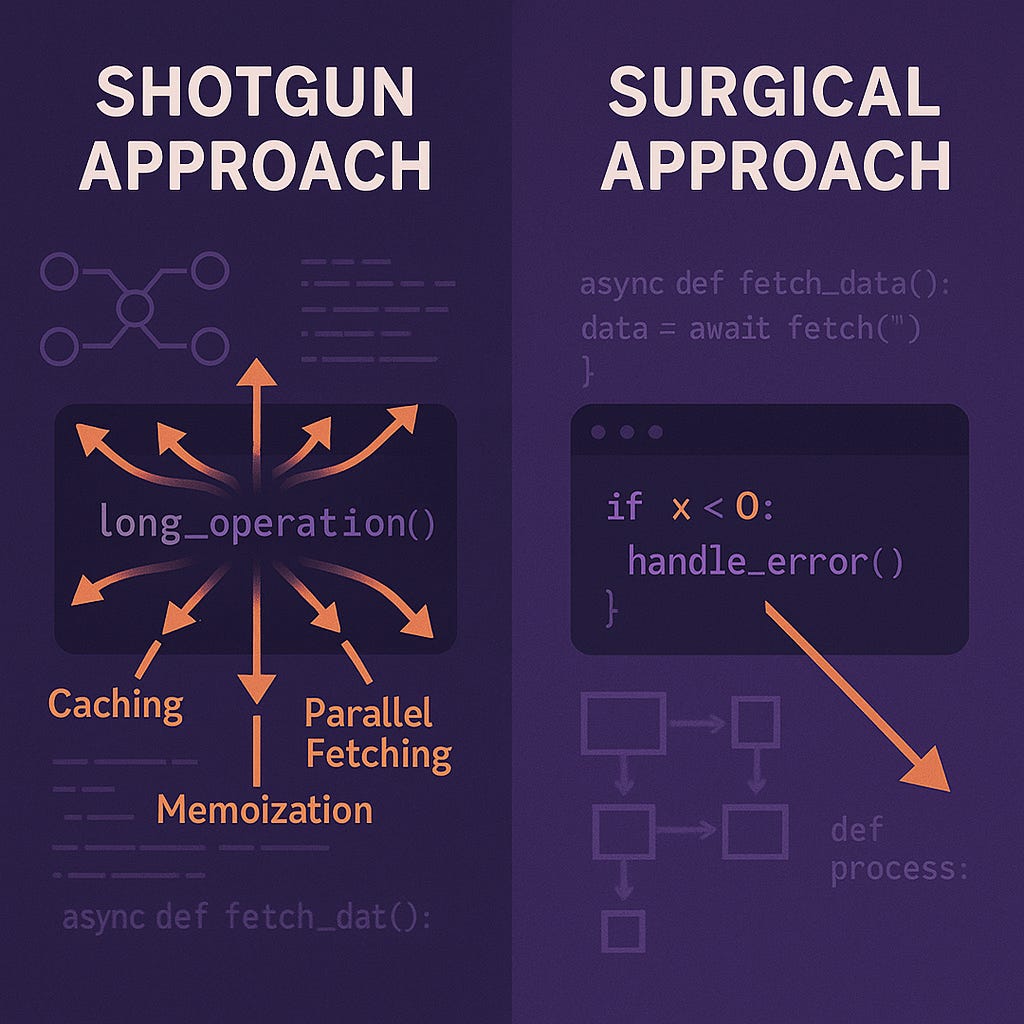
A tale of two debugging approaches
The problem seemed straightforward enough: code fetching content from a WordPress site was running slowly. Claude, the AI agent, approached it probabilistically, generating hypothesis after hypothesis based on pattern matching from its training data. It suggested optimizing API calls, implementing aggressive caching, checking for network timeouts, examining data fetching patterns—essentially throwing a comprehensive troubleshooting checklist at the content fetching problem. Each suggestion was reasonable, drawn from the vast corpus of performance optimization issues it had seen before.
Claude's AI approach: Optimize everything
Here's how Claude tackled the problem:
// Claude's probabilistic optimization approach
function Posts() {
// Hypothesis 1: Parallel fetching will solve waterfall loading
const [featuredCategoryId, setFeaturedCategoryId] = useState(-1); // Start optimistically
// Hypothesis 2: Aggressive caching prevents redundant requests
const SWR_CONFIG = {
revalidateOnFocus: false,
revalidateOnReconnect: false,
dedupingInterval: 60000, // 60-second cache
};
// Hypothesis 3: Fetch everything in parallel
const { data: categories } = useSWR(categoriesUrl, fetcher, SWR_CONFIG);
const { data: posts } = useSWR(
`${postsUrl}?categories_exclude=${featuredCategoryId}`,
fetcher,
SWR_CONFIG
);
// Hypothesis 4: Memoize expensive operations
const parsedTitle = useMemo(() => parseHtml(title, {}), [title]);
const formattedDate = useMemo(() => formatDateString(date), [date]);
// Hypothesis 5: Prefetch for faster navigation
return <Link href={`/posts/${slug}`} prefetch={true}>
}
// Result: 7.2s → 133ms (98% improvement)
// But: Didn't fix the root cause
Claude's solution was comprehensive, addressing multiple potential bottlenecks simultaneously. It applied every optimization pattern in its training data, achieving dramatic performance improvements through brute force.
Oswaldo's human approach: Find the root cause
Oswaldo took a different path entirely. Instead of following a probabilistic decision tree, he used judgment. He noticed something subtle in the symptoms that pointed to a specific bottleneck in the data fetching logic. Where Claude saw a universe of equally probable causes, Oswaldo's experience let him recognize a familiar pattern and zero in on the actual issue.
// Oswaldo's targeted fix approach
function Posts() {
// Root cause analysis: SWR hanging on malformed requests
// Replace problematic SWR with direct control
const [categories, setCategories] = useState(null);
const [categoriesIsLoading, setCategoriesIsLoading] = useState(true);
useEffect(() => {
const fetchCategories = async () => {
try {
setCategoriesIsLoading(true);
const response = await fetch(
`${process.env.NEXT_PUBLIC_BLOG_URL}/wp-json/wp/v2/categories`
);
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const data = await response.json();
setCategories(data);
// Set featured category ID after successful fetch
const featuredCategory = data.find(category => category.slug === "featured");
if (featuredCategory) {
setFeaturedCategoryId(featuredCategory.id);
}
} catch (error) {
console.error("Failed to fetch categories:", error);
setCategories(null);
} finally {
setCategoriesIsLoading(false);
}
};
fetchCategories();
}, []); // Fresh data on mount, no caching to hide issues
// Keep SWR for posts but with correct parameters
const { data: posts } = useSWR(
featuredCategoryId
? `${url}?categories_exclude=${featuredCategoryId}`
: null, // Only fetch when featuredCategoryId is ready
fetcher,
{
revalidateOnFocus: false,
dedupingInterval: 0, // No aggressive caching hiding bugs
}
);
}
// Result: Fixed 5-minute hang, immediate new post visibility
// Method: Identified and fixed the actual bug
The result? Oswaldo solved the problem with a handful of precise changes. Claude would have eventually gotten there too, but probably after writing twice as much code and exploring multiple dead ends.
This isn't a story about AI failure—it's about understanding what judgment means in engineering and why it matters.
Judgment operates where probability struggles
Recent research from cognitive science reveals something fascinating about how expert programmers think. The RIKEN Brain Science Institute found that experienced developers literally develop specialized neural circuits in the caudate nucleus, creating what amounts to "special-purpose hardware" for rapid, unconscious pattern recognition. When Oswaldo looked at that content fetching issue, his brain wasn't calculating probabilities—it was firing specialized neurons that had been shaped by years of similar problems.
This biological reality explains why the METR study's findings shouldn't surprise us. When experienced open-source developers used frontier AI tools (Cursor Pro with Claude 3.5 Sonnet) on mature codebases, they were 19% slower than working without AI assistance. Even more telling: developers thought they were 20% faster despite the measured slowdown. We're so enamored with the promise of AI that we're literally deceiving ourselves about its current effectiveness.
The difference comes down to mental models versus pattern matching. As Sean Goedecke notes, what distinguishes excellent programmers is "the accuracy and sophistication of the programmer's mental model." Humans maintain three distinct types of mental models when coding: framework models (how Rails works), code models (how this specific function executes), and domain models (what the business actually needs). AI has none of these—just statistical correlations between text patterns.
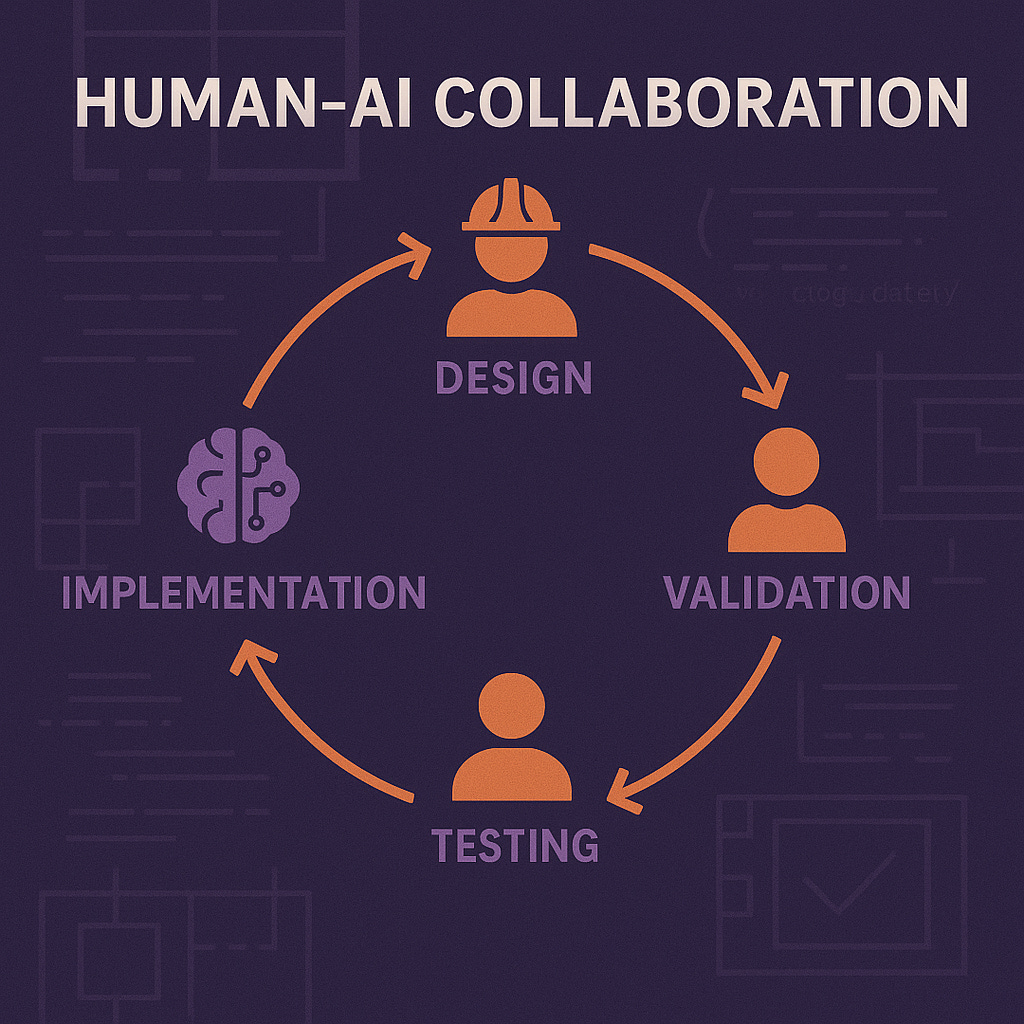
Debugging approaches compared
// AI Debugging Pattern: Shotgun approach
function debugPerformance() {
const optimizations = [
() => implementParallelFetching(),
() => addAggressiveCaching(),
() => memoizeExpensiveOperations(),
() => addPrefetching(),
() => optimizeNetworkRequests(),
() => implementLoadingStates(),
() => addErrorBoundaries(),
];
// Apply all optimizations simultaneously
optimizations.forEach(opt => opt());
// Result: Better metrics, but root cause still exists
}
// Human Debugging Pattern: Surgical approach
function debugPerformance() {
// 1. Observe symptoms
console.log("Network tab shows 5-minute hanging requests");
// 2. Form hypothesis based on experience
// "SWR configuration issues cause this pattern"
// 3. Test hypothesis directly
const suspiciousCall = useSWR(url, fetcher, config);
// 4. Isolate and fix root cause
if (config.missing || params.malformed) {
return fixSWRConfiguration();
}
// Result: Problem solved at the source
}
Where AI coding agents actually deliver value
Before you think I'm advocating abandoning AI tools, let me be clear: AI coding assistants have transformed specific aspects of development, and denying their value would be equally misguided. The key is understanding where probabilistic approaches excel and where judgment remains irreplaceable.
AI dominates in well-defined, constrained spaces. When Diffblue used AI to generate 4,750+ tests, they saved 132 developer days. Why? Because unit test generation from specifications is largely pattern matching—exactly what AI does best. Similarly, GitHub Copilot users report 70% time savings on boilerplate code, API client generation from OpenAPI specs, and documentation. These are tasks where "good enough" based on common patterns is actually good enough.
// Where AI excels: Pattern-based code generation
function generateTestSuite(apiSpec) {
// AI can reliably generate this from patterns:
describe('User API', () => {
it('should create user with valid data', async () => {
const userData = { name: 'John', email: 'john@example.com' };
const response = await createUser(userData);
expect(response.status).toBe(201);
expect(response.body).toMatchObject(userData);
});
it('should return 400 for invalid email', async () => {
const userData = { name: 'John', email: 'invalid-email' };
const response = await createUser(userData);
expect(response.status).toBe(400);
});
// ... 47 more similar tests generated in minutes
});
}
// Where AI struggles: Business logic requiring judgment
function calculatePricing(user, product, context) {
// Requires understanding of:
// - Business rules that aren't in training data
// - Edge cases specific to this domain
// - Trade-offs between accuracy and performance
// - Integration with existing pricing logic
if (context.isBlackFriday && user.hasLoyaltyCard) {
// Should this stack with other discounts?
// How does this affect our margins?
// What about regional pricing differences?
// AI can't make these judgment calls
}
}
The real wins come from what I call the "30-minute rule"—tasks that would take a human roughly 30 minutes show the highest AI success rates. These are substantial enough to benefit from automation but simple enough that AI's lack of deep understanding doesn't matter. Generate CRUD endpoints? Perfect. Write migration scripts? Excellent. Design a distributed system's failure recovery strategy? Not so much.
Multi-agent environments show particular promise when properly constrained. JM Family's BAQA Genie system cut development cycles from weeks to days by using specialized agents for requirements, coding, documentation, and QA. But notice the pattern: each agent handles a well-defined slice of the problem. When AI agents stick to their lanes, they can be remarkably effective.
The architecture of future human-AI collaboration
The path forward isn't AI versus human—it's designing workflows that leverage each side's strengths. Anthropic's research on "workflows versus agents" provides a crucial insight: predefined workflows with human checkpoints consistently outperform fully autonomous agents on complex tasks. Their evaluator-optimizer pattern, where AI generates and humans review in iterative loops, points toward a sustainable model for AI-assisted development.
Effective Human-AI Collaboration Workflow:
Human defines the architecture (judgment required) - Set technical direction and constraints
AI generates implementation (pattern matching) - Write code following established patterns
Human reviews and validates (judgment required) - Ensure business logic and edge cases are handled
AI generates comprehensive tests (pattern matching) - Create test coverage based on code structure
Human reviews test coverage (judgment required) - Verify tests actually validate important behaviors
Anti-pattern: Full autonomy without checkpoints Asking AI to handle the entire feature development process without human oversight often fails because AI lacks business context, domain knowledge, and judgment about trade-offs.
Think of it as the difference between hiring a junior developer and installing a power tool. You don't expect your nail gun to design the house, but you'd be foolish to frame it with a hammer. Similarly, AI excels at the mechanical aspects of coding—syntax, patterns, boilerplate—while humans handle the judgment calls about architecture, trade-offs, and business logic.
Test-driven development with AI represents this sweet spot perfectly. Humans define the test cases (judgment about what matters), AI writes the failing tests (pattern matching), humans review and commit (quality control), then AI implements the code (mechanical execution). Each party does what they do best.
Prompting adjustments that close the gap
If we accept that AI will often write more verbose, less elegant code than experienced developers, can we prompt our way to better results? The research suggests yes, but with caveats.
The most effective prompting strategies share a common thread: they inject human judgment into the AI's process. OpenAI's Q&A strategy works because it forces the AI to surface its assumptions for human validation. Role-based prompting ("Act as a security engineer") provides the context that AI lacks naturally. Incremental refactoring with human checkpoints prevents the cascade of "almost right" solutions that plague autonomous generation.
// Ineffective: Open-ended prompting
"Fix the performance issue in this code"
// Effective: Constrained prompting with context
`You are a senior React developer. This component fetches data from WordPress.
CONTEXT: The component should load in under 500ms but currently takes 7+ seconds.
SYMPTOMS: Network tab shows hanging requests to /wp-json/wp/v2/categories
CONSTRAINT: Keep existing functionality, only fix the performance issue
Review this code and identify the root cause:
[code here]
Before proposing a solution, ask yourself:
1. What specifically is causing the hanging request?
2. Is this a caching issue, API issue, or configuration issue?
3. What's the minimal change that fixes the root cause?`
// AI now has the context and constraints needed for targeted analysis
Here's what actually works: constrain the solution space, provide rich context, avoid open-ended tasks, and always maintain human review. When developers remember that AI is a powerful pattern matcher, not a thinking engineer, they can craft prompts that play to its strengths. Ask it to implement a specific algorithm, not to decide which algorithm to use. Have it write code that passes existing tests, not design the testing strategy.
My biggest prompting adjustments these days are trying to get AI to write less code and to review solutions more thoroughly. Until AI gets "smarter" at judgment, constraining the scope and requiring explicit validation steps works better than expecting autonomous brilliance.
Economic reality check and industry implications
The economic data presents a striking paradox. McKinsey projects $6.1-7.9 trillion in economic benefits from generative AI, yet our content fetching case study and the METR research show experienced developers getting slower with AI assistance. How do we reconcile this?
The answer lies in distribution and task selection. AI dramatically accelerates junior developers and helps seniors with routine tasks, but it can actively hinder experts working on complex problems. GitHub's data shows 41% faster task completion for new developers but much smaller gains for experienced ones. The revolution isn't in replacing senior engineers—it's in amplifying junior productivity and eliminating routine work.
This has profound implications for team composition. Companies that treat AI as a senior engineer replacement will struggle. Those that use it to give junior developers senior-level productivity on appropriate tasks will thrive. The optimal team might be fewer, more senior engineers focused on architecture and judgment calls, supported by AI handling implementation details and routine code generation.
// Traditional team structure
const team = {
seniors: 3, // Architecture + complex features
mids: 5, // Feature implementation
juniors: 4, // Bug fixes + simple features
productivity: 1.0
};
// AI-augmented team structure
const aiTeam = {
seniors: 3, // Architecture + judgment calls (100% human)
mids: 3, // Review AI code + complex integration (-40% count, +50% productivity)
juniors: 2, // Partner with AI on implementation (-50% count, +200% productivity)
ai: 'unlimited', // Pattern matching + boilerplate generation
productivity: 1.8
};
What this means for agentic coding's future
Industry predictions suggest we'll achieve "superhuman coder" capabilities by 2027, with AI matching or exceeding human programmers on most tasks. I'm skeptical, not of AI's trajectory but of what "most tasks" means. If we define programming as syntax and pattern implementation, then yes, AI will dominate. If we define it as understanding business needs, making architectural trade-offs, and debugging complex systems, we're much further away.
Consider the fundamental challenge: every new business requirement, every edge case, every integration with legacy systems requires judgment that can't be pattern-matched from training data. The more successful AI becomes at routine coding tasks, the more valuable human judgment becomes for everything else.
Tasks AI will likely master by 2027:
Generate boilerplate code and scaffolding
Write comprehensive unit tests from specifications
Implement standard CRUD operations
Generate documentation from code and comments
Refactor code using established patterns
Translate code between programming languages
Tasks requiring human judgment indefinitely:
Define business requirements and user needs
Make architectural trade-offs and technology choices
Debug novel failure modes and edge cases
Optimize for specific performance constraints
Integrate with legacy systems and undocumented APIs
Handle regulatory compliance and security requirements
Neurosymbolic AI and reasoning models like OpenAI's o3 represent genuine advances, achieving Grandmaster-level performance on competitive programming. But these systems require millions of tokens per task, highlighting the massive computational inefficiency compared to human judgment. Evolution spent millions of years optimizing biological neural networks for efficiency. We're trying to replicate that with brute force computation.
Practical recommendations for developers and teams
For individual developers navigating this landscape:
Start with AI on low-stakes, well-defined tasks. Use it to learn new frameworks and APIs where its pattern matching helps you recognize common idioms. Leverage it for test generation and documentation where "good enough" truly is good enough. But maintain your judgment skills—they're your competitive advantage. The developers who thrive will be those who can orchestrate AI tools while maintaining the ability to dive deep when judgment is required.
Practice prompt engineering, but don't expect prompting to solve fundamental limitations. No prompt will give AI the judgment to know when a content fetching issue stems from a specific SWR configuration versus a network timeout. That recognition comes from experience encoded in neural pathways, not statistical patterns in training data.
For engineering teams implementing AI coding tools:
Adopt GitHub's four-stage framework: evaluate with volunteers, scale gradually, optimize workflows, then sustain improvements. But customize it for your context. Mature codebases with implicit requirements need different strategies than greenfield projects. The METR study's 19% slowdown happened on 10+ year old codebases with millions of lines of code—your mileage will vary.
Invest heavily in documentation and testing—these become the interfaces through which AI understands your system. Clear coding standards help AI generate consistent code. Comprehensive tests let you safely experiment with AI-generated changes. Think of it as creating an operating manual for your AI assistant.
Most critically, measure actual productivity, not perceived benefits. The gap between developer perception and reality in the METR study should alarm every engineering manager. Track not just speed but also bug rates, code review time, and long-term maintenance costs. AI that generates code 50% faster but requires 100% more debugging time is a net negative.
// Effective AI integration metrics
const metrics = {
// Traditional metrics (insufficient alone)
codeVelocity: '+40%',
ticketsCompleted: '+25%',
// Essential quality metrics
bugEscapeRate: '-15%', // Good: AI catches simple bugs
codeReviewTime: '+30%', // Concerning: More review needed
technicalDebt: '+10%', // Warning: Monitor closely
// Business impact metrics
timeToMarket: '+20%',
customerSatisfaction: 'stable',
maintenanceCost: '+5%' // Acceptable trade-off
};
The bottom line on where we are and where we're going
We're at an inflection point where AI coding tools are simultaneously overhyped and underutilized. They're overhyped as replacements for engineering judgment and underutilized as amplifiers of human capability. The content fetching case study isn't an argument against AI—it's an argument for understanding what makes human engineers valuable and using AI to handle everything else.
The current state of agentic coding is powerful pattern matching without judgment. AI will solve your problems, but often inelegantly, verbosely, after exploring paths that didn't need exploring. For tasks where patterns work—much of programming's mechanical work—this changes everything. For tasks needing judgment, context, and elegant solutions, experienced engineers aren't going anywhere.
The engineers who will thrive in this new landscape are those who understand this distinction viscerally. They'll use AI to handle the probabilistic pattern matching while reserving their judgment for the decisions that matter. They'll write less code but make more architectural decisions. They'll debug less syntax but spend more time on system design.
This isn't simply a temporary state awaiting better AI. Even as AI capabilities advance toward the predicted "superhuman coder" of 2027, the gap between pattern matching and judgment will persist. The question isn't whether AI will replace programmers but how the profession will evolve when the mechanical aspects are automated. Based on the content fetching tale and thousands of similar stories playing out across the industry, that evolution will be messier, more gradual, and ultimately more human than the AI evangelists predict.
The future of software development isn't AI or human—it's AI and human, each doing what they do best. Understanding that distinction, and designing our tools and workflows around it, is the real challenge of agentic coding. Those who get it right will write less code but build better systems. Those who don't will generate twice as much code to solve problems that judgment could have handled in a few precise lines.
Related Reading
On AI Tool Evolution & Market Reality:
The Other Shoe Will Drop - Why current AI pricing economics are unsustainable
Around the Horn: AI Coding Tools Reality Check - Recent market developments and tool performance
On Debugging & Tool Reliability:
The Ghost in the Machine: Non-Deterministic Debugging - When AI tools behave unpredictably
What's In My Toolkit - August 2025 - Current tool setup and why specific choices matter
On AI Orchestration vs Direct Usage:
I Hope Never To Use Claude Code Again - Moving from individual AI assistants to orchestrated teams
Multi-agent AI Orchestration in Practice - Real-world experiences with coordinated AI development