



I was three hours into debugging my AI code review tool when I hit the wall that every AI engineer knows too well. The model just wouldn't follow my intent, no matter how clearly I explained it.
The problem was deceptively simple: I needed the AI to evaluate developer skills, not provide code improvements. But despite explicitly stating "analyze the code to assess the developer's skill level" and "provide insights into coding maturity without suggesting improvements," Claude kept slipping back into helpful mode. Every response mixed assessment with suggestions like "consider using async/await here" or "this could be optimized by..."
Three hours of prompt tweaking. Multiple attempts at rewording. Still getting hybrid evaluation-improvement responses that defeated the entire purpose.
Then I tried something that felt almost silly: I added the word "FORBIDDEN."
FORBIDDEN: Do not suggest any improvements, fixes, optimizations, or changes to the code. Focus solely on assessment.
Instantly, the responses shifted. Clean assessments. Pure skill evaluation. No improvement suggestions bleeding through. The AI finally understood the hard boundary I'd been trying to establish for hours.
What I discovered accidentally, recent research has now proven systematically.

When "Nice" Prompts Fail
My original prompt was perfectly reasonable by conventional standards:
Analyze the provided code to assess the developer's skill level, experience, and potential use of AI assistance tools. Provide insights into coding maturity, decision-making quality, and development approach without suggesting improvements.
Polite. Clear. Professional. And completely ineffective for maintaining the boundary between evaluation and improvement.
The problem wasn't clarity—it was definitiveness. AI models, especially helpful ones like Claude and GPT-4, are trained to be assistive. When they see code, the default behavior is to help improve it. My gentle "without suggesting improvements" was too weak to override that fundamental training.
The psychological principle at work here mirrors human behavior. Soft guidelines ("try to avoid") get interpreted as suggestions. Hard boundaries ("forbidden") create constraints that actually stick.

The Research Behind Strong Directives
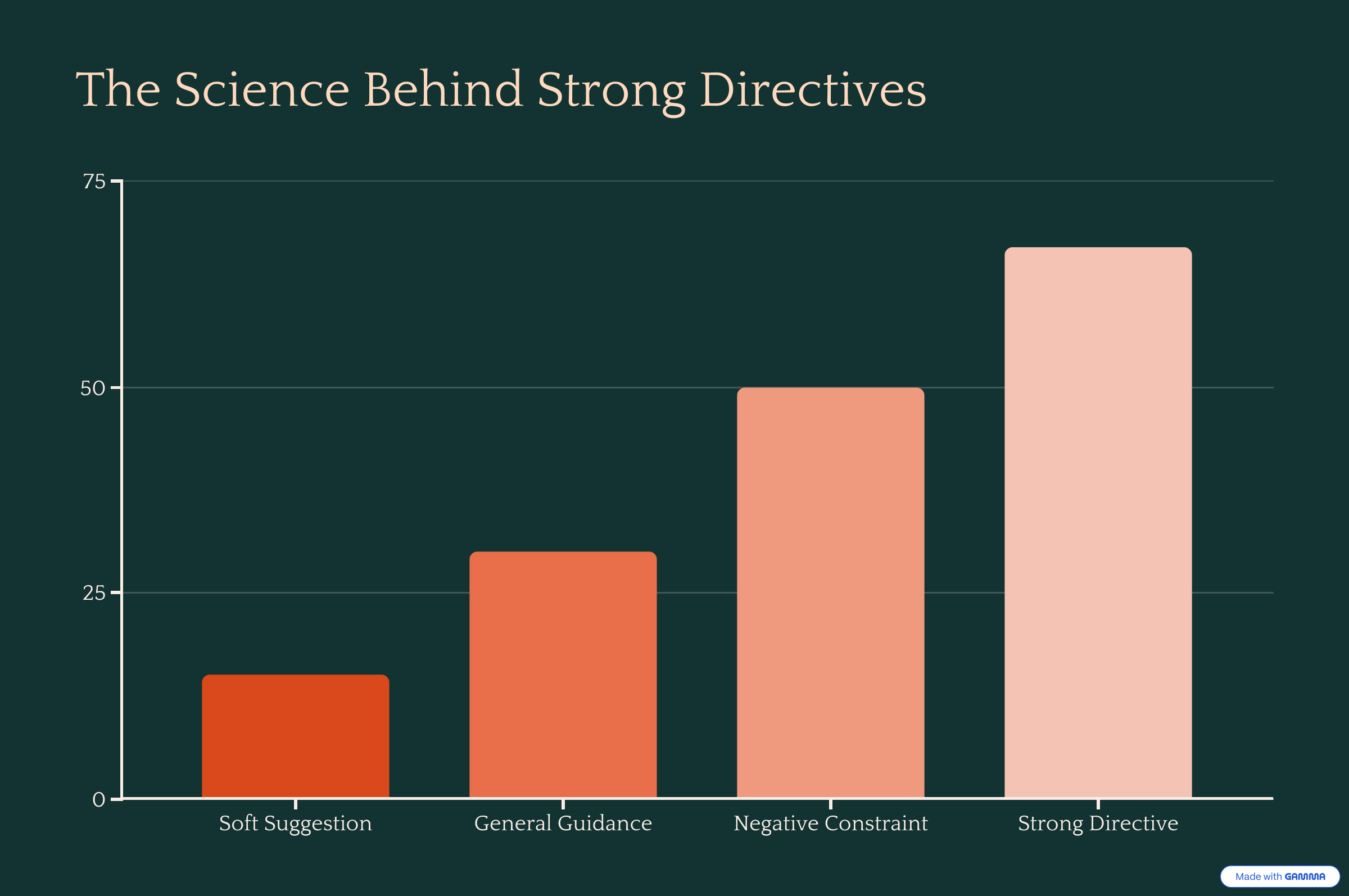
A landmark study published on arXiv testing 26 prompt engineering principles across GPT-4, GPT-3.5, and LLaMA models found something counterintuitive: positive, affirmative directives outperform negative ones by 50-67%, but when you need hard constraints, strong negative language works significantly better than weak alternatives.
The key finding: "Employ affirmative directives such as 'do,' while steering clear of negative language like 'don't'" produced remarkable improvements for general instruction following. But for constraint enforcement—exactly my use case—definitive negative language like "forbidden," "never," or "must not" creates cleaner boundaries.
Microsoft Research's attention analysis of extensive prompt datasets revealed why. Models show stronger attention patterns to high-salience constraint words. "Forbidden" has higher cognitive weight than "avoid" or "don't." The AI literally pays more attention to it.
My Solution: Graduated Force
Here's what actually worked in my final prompt:
🧠 **Code Evaluation Review**
CRITICAL: This is a DEVELOPER ASSESSMENT review, NOT a code improvement review.
You must ONLY assess the developer's skills and characteristics.
DO NOT provide any suggestions, recommendations, or improvements to the code.
Act as an expert technical lead with extensive experience in developer assessment
and code analysis. Your task is to analyze the provided code to assess the
developer's skill level, experience, and potential use of AI assistance tools.
FORBIDDEN: Do not suggest any improvements, fixes, optimizations, or changes
to the code. Focus solely on assessment.
Notice the escalating language:
CRITICAL establishes immediate importance
DO NOT provides clear negative instruction
FORBIDDEN reinforces the hardest constraint
This isn't about being aggressive with the AI. It's about using language that creates unambiguous boundaries when you need them.

When to Use Strong Directives
The research and my experience suggest strong directive language works best in three scenarios:
1. Mode Switching When you need the AI to operate in a fundamentally different mode than its default behavior. Evaluation vs. improvement, analysis vs. generation, factual reporting vs. creative writing.
2. Safety-Critical Constraints Compliance requirements, privacy boundaries, or any scenario where breaking the constraint has real consequences. Financial advice disclaimers, medical information boundaries, data privacy rules.
3. Output Format Enforcement When you need specific, non-negotiable output structures. JSON formatting, specific response templates, character limits that can't be exceeded.

The Positive-Negative Balance
The most effective prompts combine both approaches strategically. Use positive directives for what you want the AI to do, then strong negative language for absolute boundaries:
Effective combination:
Analyze the code quality and suggest three specific improvements.
FORBIDDEN: Do not modify the original code directly.
Less effective:
Please analyze the code and try to suggest improvements while avoiding
direct modifications to the original code.
The first example gives clear positive direction (analyze + suggest) with a hard constraint (forbidden direct modification). The second muddles everything together with soft language.

Enterprise Applications
The research on directive language has direct practical applications. OpenAI's official prompting guide emphasizes clear, direct instructions over aggressive language, while Anthropic's Constitutional AI approach uses precisely structured positive principles.
For safety-critical applications, the combination of research findings and practical testing shows clear patterns. When compliance matters, definitive negative language creates more reliable boundaries than soft suggestions.
Implementation Guidelines
Based on systematic testing research and multiple framework studies on constraint satisfaction in language models, here's what works:
Hierarchy of Directive Strength:
Specific positive directives ("Generate exactly three JSON objects")
Strong negative constraints ("FORBIDDEN: No personal opinions")
General positive guidance ("Focus on factual analysis")
Soft suggestions ("Try to avoid speculation")
Optimal Structure:
Lead with positive instructions (what to do)
Follow with strong constraints (what never to do)
End with context or examples
Language That Works:
FORBIDDEN / NEVER / MUST NOT for hard boundaries
CRITICAL / IMPORTANT for priority signaling
Specific verbs (analyze, generate, list) over vague ones (consider, try)
The research on constraint frameworks shows that models struggle significantly with more than 10 simultaneous constraints, suggesting that constraint prioritization matters more than constraint strength.
Beyond Politeness
The broader lesson here challenges conventional wisdom about AI interaction. We're taught to be polite with AI, to phrase requests gently, to say "please" and "thank you." For general interaction, that's fine. But when you need reliable constraint adherence, clarity and definitiveness matter more than courtesy.
This isn't about anthropomorphizing AI or treating it like a stubborn employee. It's about understanding how language models actually process instructions and using that knowledge to get better results.
The word "forbidden" worked in my code review tool because it created an unambiguous constraint that the model's attention mechanisms could latch onto. No ambiguity, no wiggle room, no helpful suggestions bleeding through.
Sometimes the magic word isn't "please." Sometimes it's "forbidden."

Bottom Line
Strong directive language isn't about being aggressive with AI—it's about being precise. When you need hard boundaries, use hard language. When you need the AI to switch modes completely, make that transition unambiguous. When the stakes are high, definitiveness trumps politeness.
My three hours of debugging could have been three minutes if I'd understood this principle from the start. The research validates what many practitioners have discovered through trial and error: sometimes you need to be direct with AI to get the behavior you actually want.
The next time your AI isn't following constraints, try escalating your language. You might be surprised how well "forbidden" works.