

Wrapped 2025: The Year of the Hyperdev
My own personal journey


TL;DR
Started March with a 12-hour experiment and 4,000 lines of AI-generated code. Ended December with 4,919 commits, 24.7 million net lines, 168 published articles, and 69.7 billion tokens processed.
Four months of messy experimentation preceded the real inflection point: Claude Code shipping context filtering in mid-July. Haven’t stopped building since.
The MCP ecosystem paid off: mcp-vector-search, kuzu-memory, and mcp-ticketer became foundational. mcp-browser got obsoleted by Chrome DevTools MCP. That’s how it goes.
The economics tell a story: $45,000 at rack API rates, ~$8,000 actual cost through Max subscriptions. An 82% subsidy from Anthropic and OpenAI. I’m exactly the heavy user these companies lose money on—and I’m getting 4-6x ROI even at the rates they’re not charging me.
The writing found an audience: 372,000 LinkedIn impressions (+703% YoY), 44-46% Substack open rates, ~150,000 combined unique reach.
2026 prediction: CLI-agentic coding goes mainstream. The patterns that felt experimental this year become standard practice.
Where It Started
In March, I published “Fear and Loathing in Hyperdev-land” on LinkedIn. The premise was simple: I hadn’t coded seriously in 20 years. Could I build a working application using AI tools in a single sitting?
Twelve hours later, I had a deployed travel planning app. Over 4,000 lines of mostly AI-generated code. The thing actually worked.
The post got 99 reactions and 28 comments. One response stuck with me. Richard Wang wrote: “’AI allows a non-engineer to build a product without coding’ is a hype... ‘AI can improve a developer’s productivity by 10x’ is true.”
He was right. And wrong. The real answer turned out to be more interesting than either framing.
The Numbers
Here’s what 2025 looked like in raw output:
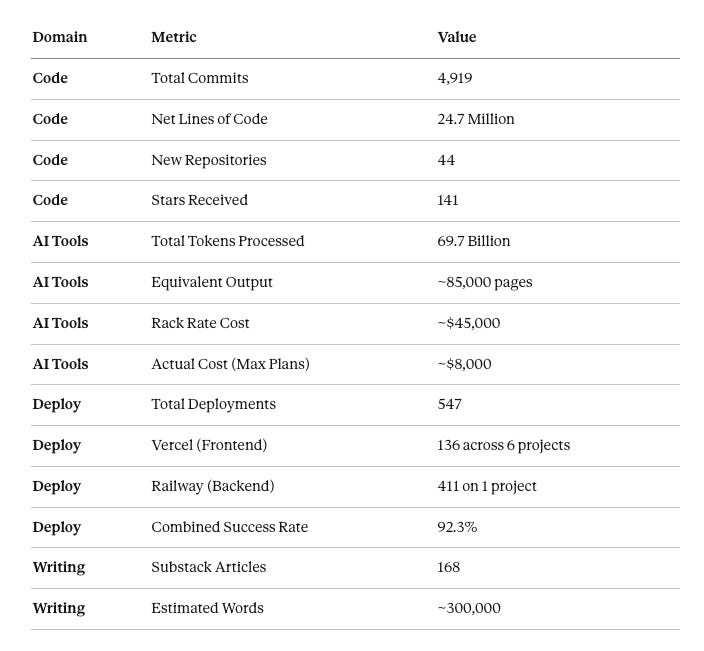
That’s roughly 20 commits per working day. 3.2 articles per week. 69.7 billion tokens—enough to generate the equivalent of 85,000 pages of code and documentation.
The 547 deployments tell a story beyond the commits. The Railway number—411 deployments for a single client project over 87 days, averaging 4.7 per day—represents actual production work. Real stakes. Revenue-generating infrastructure. Not hobby projects.
December 3rd captures the whole dynamic in a single day: $525 in AI compute costs, 46 Railway deployments, and progress on three simultaneous projects. The most expensive AI day was also the most productive deployment day. That’s not a coincidence—that’s what the infrastructure enables.
The language split: 38% Python for MCP servers and CLI tools, 34% TypeScript for web interfaces, the rest scattered across Ruby, JavaScript, Shell, and some experimental Rust.
The Messy Middle
April through June was chaos.
I built things that broke. Then rebuilt them. The claude-multiagent-pm prototype worked well enough to be exciting and poorly enough to be frustrating. Every subprocess inherited the entire conversation context whether it needed it or not. Token costs were obscene. Context confusion was constant.
I experimented with memory systems. Most corrupted their own state. A few worked fine until they didn’t. One particularly annoying week involved debugging a memory persistence issue that turned out to be a race condition I’d created myself by over-engineering the solution.
The 44 new repositories from this year? Probably a third of them represent false starts or abandoned approaches. That’s how this works. You don’t find the right architecture on the first try.
What I was actually learning during those months: what not to build. Which constraints matter. Where the sharp edges live.
The Inflection Point
The experiment phase ended in mid-July.
Claude Code shipped context filtering around that time—the ability for subagents to operate in isolated context windows rather than inheriting the entire conversation. Sounds like a minor technical detail. Changed everything about how multi-agent workflows could function.
Before context filtering, my prototype burned tokens like a furnace. After? I rebuilt everything. claude-mpm emerged from that rebuild. 1,545 commits over the rest of the year. It became my actual development environment, not an experiment I occasionally tested.
That’s when the practitioner identity clicked. Not when I shipped the first prototype. Not when I published the first article. When I stopped reaching for other tools because this one just worked.
The timing wasn’t coincidental. Mid-July also brought a major platform refactoring project for a client—real production code, real stakes. I remember the specific moment it hit me: I’d just pushed a feature that I would never have taken on without a team. The whole thing, from spec to deployed, took about four hours of engaged time, a few days of agentic time. And the code was acceptable - it would have been much better with Opus 4.5, but it was good enough to change the trajectory of the startup I was advising.
By August, I was routinely contributing code to production systems and building POCs for client work. The tools I’d been developing weren’t just personal experiments anymore. They were how I delivered professional value. And when it worked well it was exhilarating.
Twenty years away from serious coding. Four months back. Contributing production code for paying clients. That’s the trajectory AI-assisted development made possible.
What Survived
Not everything I built in 2025 proved useful. The projects that earned their place:
ai-code-review: My first public project. AI-powered code review automation that integrates with multiple LLM providers. The one other developers actually adopted and contributed back to. Turns out automated code review is the kind of obvious-in-retrospect tool that people actually want. The coding tools will do just as well but require more setup. I plan to integrate it into a PR review model at some point.
claude-mpm: The flagship. A framework where specialized agents—Research, Engineer, QA, Ops, Documentation—collaborate on complex development tasks while a PM agent coordinates workflow. I use it daily. A small cohort of fellow practitioners use it too. The multi-agent thesis validated itself through sustained production use, not benchmark performance.
mcp-vector-search: Semantic code search for Claude. When you’re working across 40+ repositories, grep stops scaling. Vector search finds conceptually related code even when the naming conventions differ. Quietly essential, and has a great visualization tool.
kuzu-memory: Graph-based memory persistence for LLM sessions. Sub-3ms recall with relationship-aware context retrieval. Most memory systems treat knowledge as flat documents. Kuzu treats it as connected entities. The difference matters when you’re maintaining coherent context across weeks of development. It also runs on hooks and has no context cost, which I’m now realizing is important as mcp systems proliferate.
mcp-ticketer: Integration with Linear, GitHub Issues, Jira, Asana. This became the foundation for Ticket-Driven Development—using tickets as persistent knowledge containers for human-AI collaboration rather than just task assignments. When an agentic session ends, the context typically evaporates. TkDD captures the evolution of thinking in a place that survives session boundaries.
What Didn’t Survive
mcp-browser was probably my most technically sophisticated MCP server. Browser automation, page interaction, DOM traversal. Real engineering went into it.
Then the Chrome team shipped Chrome DevTools MCP. Same capabilities, official support, better integration. My implementation became redundant overnight.
That’s how this space works. Build something useful, watch the platform absorb it, move on to the next gap. I’m not bitter—Chrome DevTools MCP is genuinely better than what I built. But it’s a reminder that in fast-moving infrastructure, timing matters as much as execution.
The memory experiments were messier. I tried at least four different approaches to maintaining context across sessions. SQLite-backed stores that got corrupted. Document databases that couldn’t handle relationship updates gracefully. A particularly over-engineered solution involving three separate caching layers that I eventually abandoned.
Kuzu-memory survived because graph databases handle relationship updates more gracefully than document stores. It’s also lightweight and automatic (uses Claude Code hooks to store and enrich). The others taught me what not to build.
edgar—my largest repository by raw code volume at 15.4 million lines—represents something different. SEC EDGAR financial data analysis tooling. Massive in scale, narrow in application, useful for a specific research project but not the kind of thing that transfers to other contexts. Not every repository needs to be a framework.
The Economics
The real cost story is more dramatic than “$1,000 a month.”
At rack API rates, the 69.7 billion tokens I processed from May through December would have cost roughly $45,000. Through Max subscriptions—two Claude accounts for my own work, three from clients for their projects, plus GPT Max for specific use cases—I paid about $8,000.
That’s an 82% subsidy. Anthropic and OpenAI essentially covered $37,000 of my AI compute costs.
This is exactly the unsustainable economics I’ve written about all year. I’m the heavy user these companies lose money on. Every article about AI pricing pressures, every analysis of when the subsidy ends—I’m describing my own workflow. The 93.58% cache efficiency in my Claude Code usage shows sophisticated utilization, not random prompting. I’m optimizing their losses.
And I’m still getting 4-6x ROI even at the rack rate they’re not charging me.
For that investment: 4,919 commits. 168 articles. 44 new repositories. 547 production deployments across Vercel and Railway. Client work that generated actual revenue. The equivalent of 85,000 pages of generated output—code, documentation, analysis.
The model tiering tells its own story. I used Opus (38% of costs) for architectural decisions and complex reasoning. Sonnet (62% of costs) as the daily development workhorse. Haiku (0.2% of costs) for quick queries and navigation. They aren’t being selected randomly—it’s a deliberate choice based on task complexity. Since Opus 4.5 came out, I use it for most tasks and it ends up being more efficient than Sonnet 4.5 for most tasks. For AI enablement (as opposed to coding), I use a variety of models.
From the practitioner side? Whatever pricing corrections come in 2026, the value proposition holds. These tools make a different kind of productivity possible. The question isn’t whether to use them—it’s how to optimize before the subsidy disappears.
The Writing Machine
168 articles in 9 months sounds unsustainable until you see the workflow.
Everything runs through a single Claude.ai project. Custom system instructions. Accumulated context about HyperDev’s voice, technical focus, recurring themes. A custom GPT handles proofreading and pattern detection—flagging AI-tell words, checking sentence variety, catching the structural repetition that makes machine-assisted writing obvious.
The output: roughly 300,000 words across all the pieces. 27% focused on Claude and Anthropic. 24% on agentic AI tools broadly. 12% on multi-agent systems. The rest spread across industry economics, engineering practice, and specific project documentation.
3.2 articles per week maintained across nine months. Some weeks produced five. Some weeks produced one. The average held because the infrastructure supported it.
That’s the real lesson about AI-assisted productivity. Raw capability matters less than workflow design. The tools don’t make writing easier—they make sustainable high output possible when you build the right systems around them.
The Reach
The writing found an audience. Not a viral explosion—steady accumulation.
LinkedIn (365-day metrics):
372,343 impressions
702.8% year-over-year growth
141,959 unique members reached
19x reach multiplier against follower count
Substack:
44-46% average open rate (industry average: 30-40%)
Peak article: 507 reads (”How Claude Code Got Better”)
Estimated 40,000-60,000 total views across 168 articles
Combined unique reach: ~145,000-150,000 people, accounting for platform overlap.
The open rate matters more than raw numbers. 44-46% means nearly half the subscriber base actually reads the content. That’s not a vanity metric, it’s proof the writing delivers value worth opening.
The LinkedIn growth tells a different story. 703% year-over-year happened without any particular optimization strategy. No engagement pods. No growth hacks (well I may have boosted a few). Just consistent publishing of substantive analysis while most AI commentary stayed shallow.
Turns out there’s an audience for practitioners who actually build the things they write about.
What 2025 Proved
Multi-agent coordination works. claude-mpm’s 30 stars and 5 forks represent real practitioners finding value, not GitHub tourists clicking buttons. Daily use across six months of client work. The thesis that specialized agents collaborating outperform monolithic assistants proved itself through production, not benchmarks.
Infrastructure beats features. mcp-vector-search and kuzu-memory don’t demo well. They’re not impressive at conferences. They’re what makes sustained multi-agent work possible. The context management layer matters more than the model powering the agents. I learned this the hard way—by building flashy things that broke and boring things that lasted.
The economics work—for now. An 82% subsidy on $45,000 of compute isn’t a business model. It’s a land grab. But even at full rack rates, the 4-6x ROI holds. Whatever corrections come, the value proposition survives.
Thought leadership requires building. 168 articles wouldn’t carry weight if they were commentary from the sidelines. The credibility comes from shipping tools that others actually use, burning through 69.7 billion tokens on real projects, and documenting both the wins and the failures. Critique without practice is opinion. Practice without documentation is private learning. The combination creates something different.
The Identity Question
In March, I was a technology leader who hadn’t coded seriously in 20 years. By December, I’d shipped 44 public repositories, accumulated 141 stars, processed 69.7 billion tokens, and built tools that other practitioners depend on.
What changed? Not the underlying skills—I knew how software worked, understood architectures, could reason about system design. What changed was having AI as a force multiplier that converted that knowledge into actual artifacts.
I ended up becoming something specific: an AI infrastructure builder. Not consumer applications. Not traditional web apps. The protocols, memory systems, and orchestration frameworks that make AI-assisted development possible. That’s where the interesting problems live. That’s where I ended up.
The transition from technology executive to AI practitioner wasn’t a career change. It was an expansion. The leadership experience informs architectural decisions. The practitioner activity creates credibility. The writing amplifies both.
Looking at 2026
CLI-agentic coding goes mainstream this year.
The patterns that felt experimental in early 2025—multi-agent orchestration, persistent memory systems, ticket-driven development—will become standard practice. The tools will mature. The rough edges will smooth. What required custom infrastructure will ship as platform features.
Some specific predictions: Context windows expand enough that memory systems become less about projects and more about long term persistent workflow (and support for more integrated context-using tooling). MCP remains the default interface for LLM tool integration, but will suffer from multiple very public security failures that will require an overhaul of its security model. At least a few major multi-agentic native “IDE”s ship. The current crop of AI coding startups either get acquired or go bust—the middle ground disappears. Companies will continue to shed jobs, protectively and reactively until they understand how to normalize agentic workflows. Then aggressively.
AGI will be a phantom mostly important to VCs, but the coding, writing and productivity tools continue to get much better and by next year will be the preferred way code and other content is generated for the majority of use cases. Specialized toolchains will be the exception but there will be more opportunity, and pressure to re-platform.
The pricing correction I’ve been writing about all year finally arrives. The 82% subsidy shrinks. Heavy users like me start paying closer to rack rates. And we’ll pay it (or our companies will), because the ROI still works—just with tighter margins and more deliberate usage.
HyperDev will continue documenting the journey. 168 articles established the foundation. The trajectory isn’t slowing down.
From 12 hours of AI-assisted coding in March to 4,919 commits, 547 deployments, 168 articles, 69.7 billion tokens, and a new professional identity—2025 was the year of the Hyperdev.
I’m Bob Matsuoka, writing about agentic coding and AI-powered development at HyperDev. For more on the multi-agent thesis, read my deep dive into claude-mpm architecture or my analysis of the economics of AI-assisted development.